Get Azure Databricks Cluster connected to Azure Managed Instance for Apache Cassandra
本記事では、過去の記事でデプロイした Azure Managed Instance for Apache Cassandra に対して同じくデプロイ済みの Azure Databricks から接続をする方法を解説します。 Azure Databricks の Notebook で Cassandra に接続して CQL を発行し、それが正しく実行されていることをゴールとします。
前提
- Microsoft Azure に利用可能なサブスクリプションを持っている
- Azure Portal で操作を行う
- Get Started with Azure Managed Instance for Apache Cassandra の手順に沿って Azure Managed Instance for Apache Cassandra クラスターが作成されている
- Deploying a Virtual Machine to issue CQL to Azure Managed Instance for Apache Cassandra using cqlsh の手順に沿って Azure Managed Instance for Apache Cassandra クラスターに対して CQL を発行できる
- Getting started with Azure Databricks の手順に沿って Azure Databricks リソースが作成されている
- Create Route Tables to get Azure Databricks connected to Azure Managed Instance for Apache Cassandra の手順に沿って Azure Managed Instance for Apache Cassandra のサブネットと Azure Databricks のサブネットが相互にルーティングしている
免責
- 筆者の環境は英語です。画面が日本語表示になっていない点、ご了承ください。
- スクリーンショット内で文字列に赤の波線が引かれている部分は、ブラウザの校正機能によるものであり、記事の内容とは関係ありません。
手順
Azure Databricks にクラスターを作成する
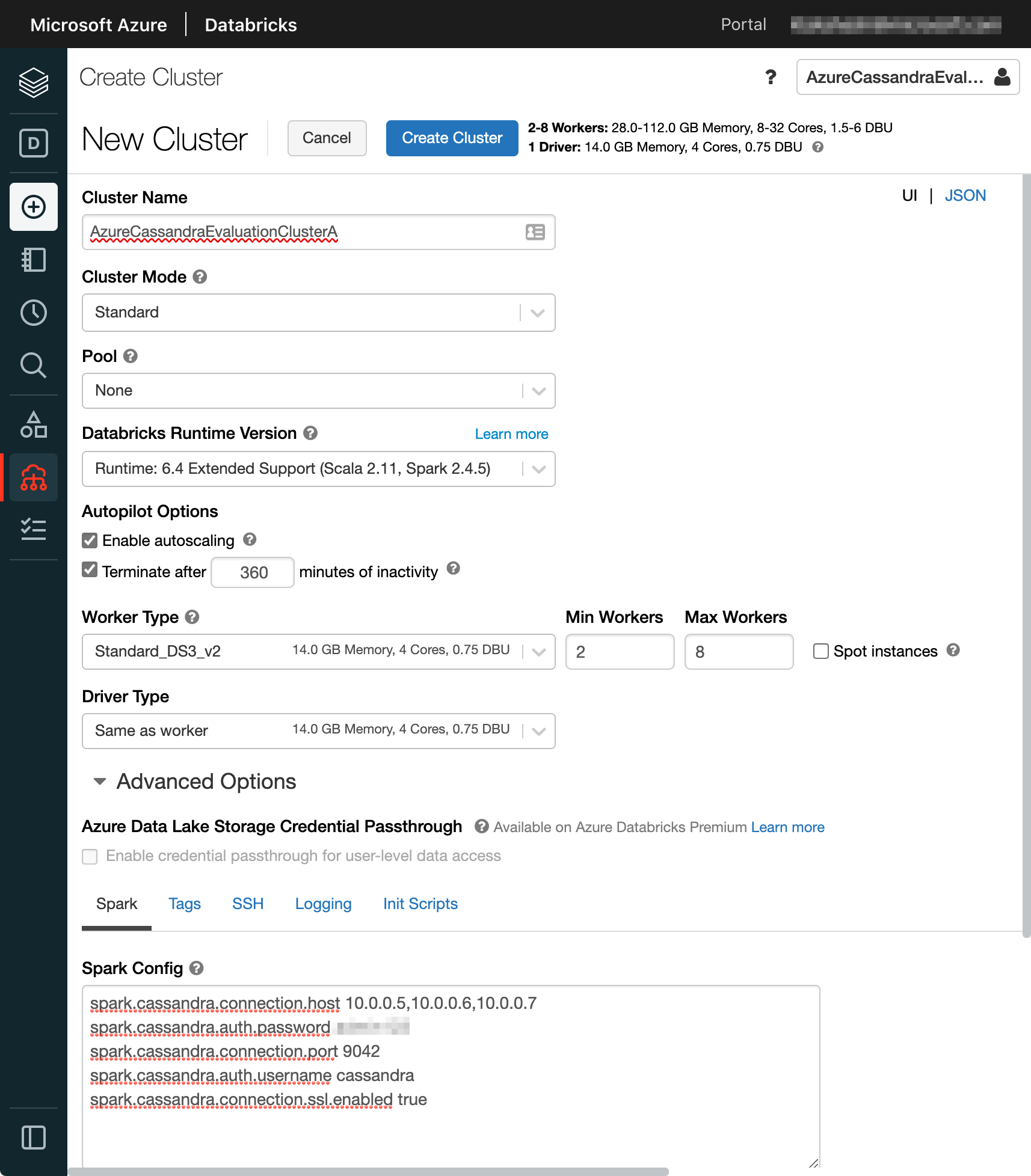
Azure Databricks の Workspace を開き、サイドバーの + アイコンからクラスターの作成を行います。その際、以下の設定を行ってください。
Databricks Runtime Versionは6.4 Extended Support (Scala 2.11, Spark 2.4.5)を選択します。これは Cassandra ライブラリとの互換性のために必要です。Spark Configに Cassandra の各種情報を記述します。項目は以下の通りです。1
2
3
4
5spark.cassandra.connection.host ${CassandraクラスターのIPアドレス(カンマ区切り)}
spark.cassandra.auth.password ${Cassandraクラスター作成時に指定したパスワード}
spark.cassandra.connection.port ${CassandraクラスターのTCPポート番号 (デフォルト:9042)}
spark.cassandra.auth.username ${Cassandraクラスターのユーザー (デフォルト:cassandra)}
spark.cassandra.connection.ssl.enabled ${SSL有効化の有無 (true必須)}
本記事の場合、クラスターの作成は約4分で完了しました。
クラスター作成完了後、クラスターの設定画面に移動する
spark-cassandra-connector をインストールする
Spark から Cassandra に接続するためのライブラリをインストールします。まずは Libraries タブをクリックします。
Install New ボタンをクリックすると、ライブラリのインストールのためのモーダルが表示されます。初期状態では Library Source が Upload タブにフォーカスされています。これを Maven に切り替えてください。
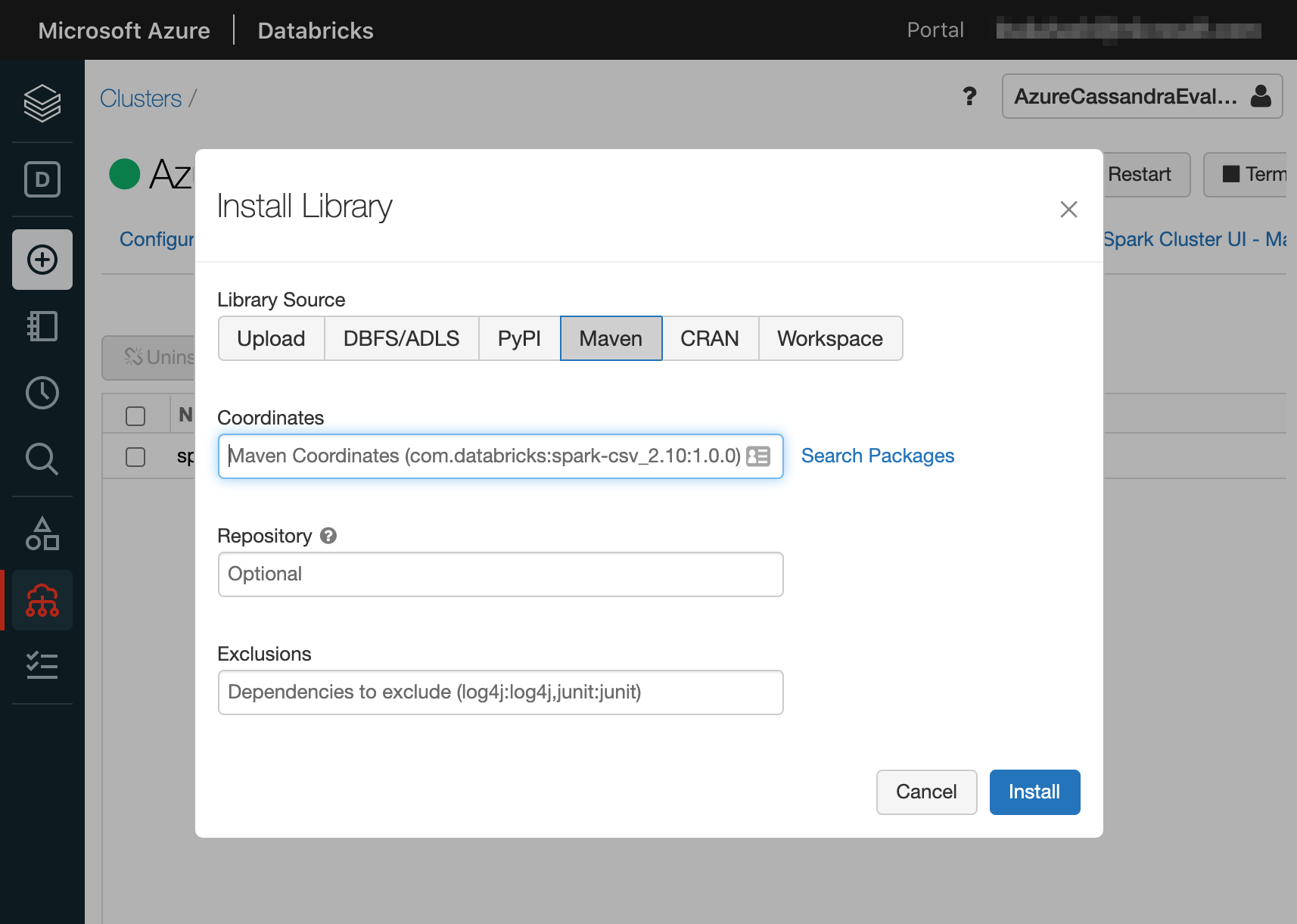
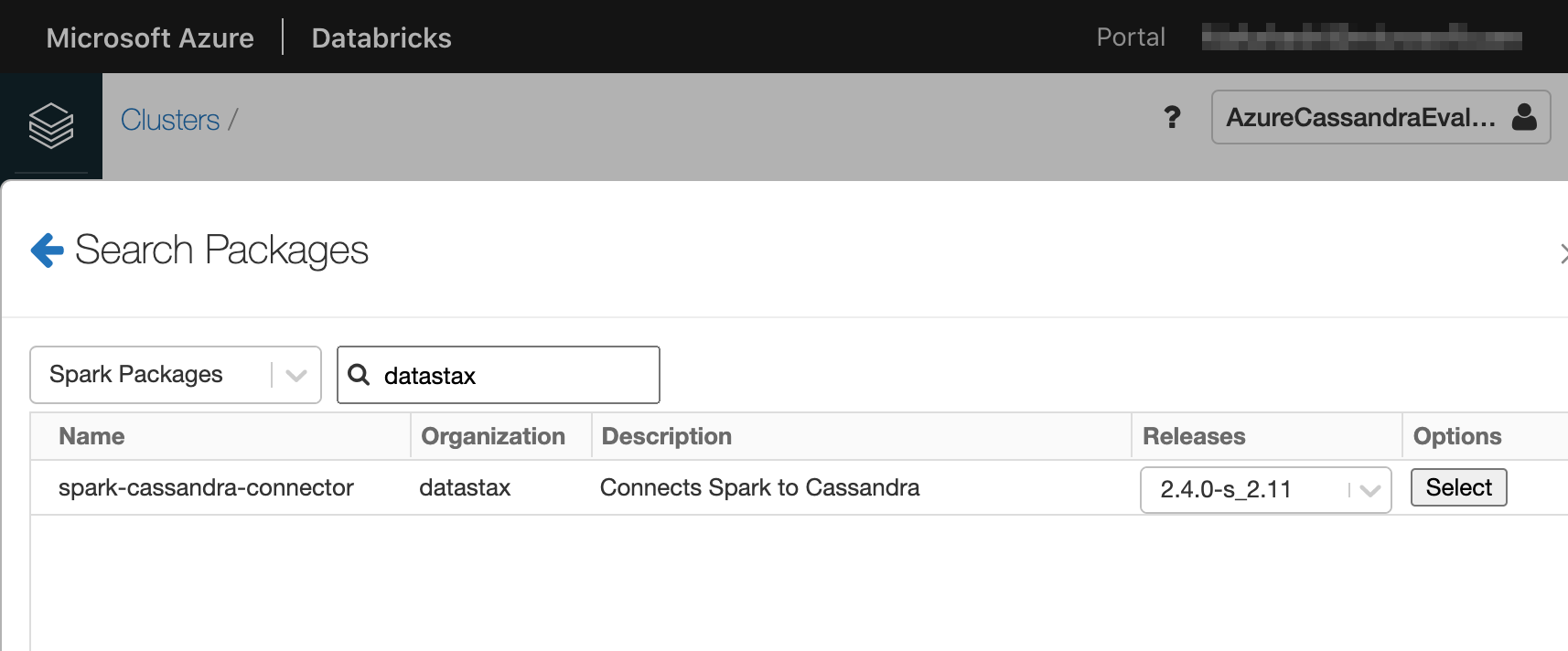
Coordinates に spark-cassandra-connector と入力して Search Packages リンクをクリックすることで、 datastax のライブラリを入力します。
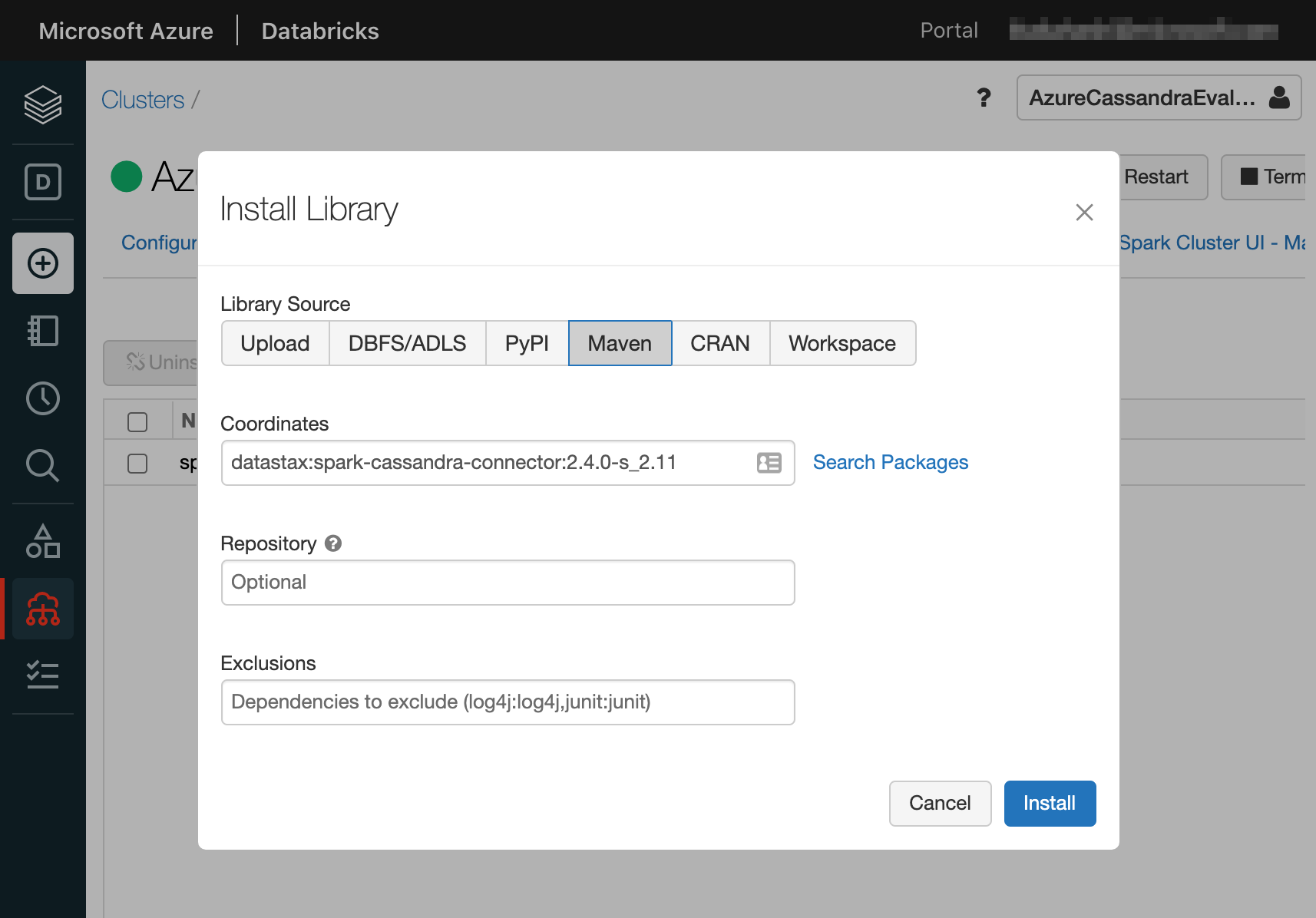
Install ボタンをクリックすると、指定したライブラリが Azure Databricks クラスターにインストールされます。
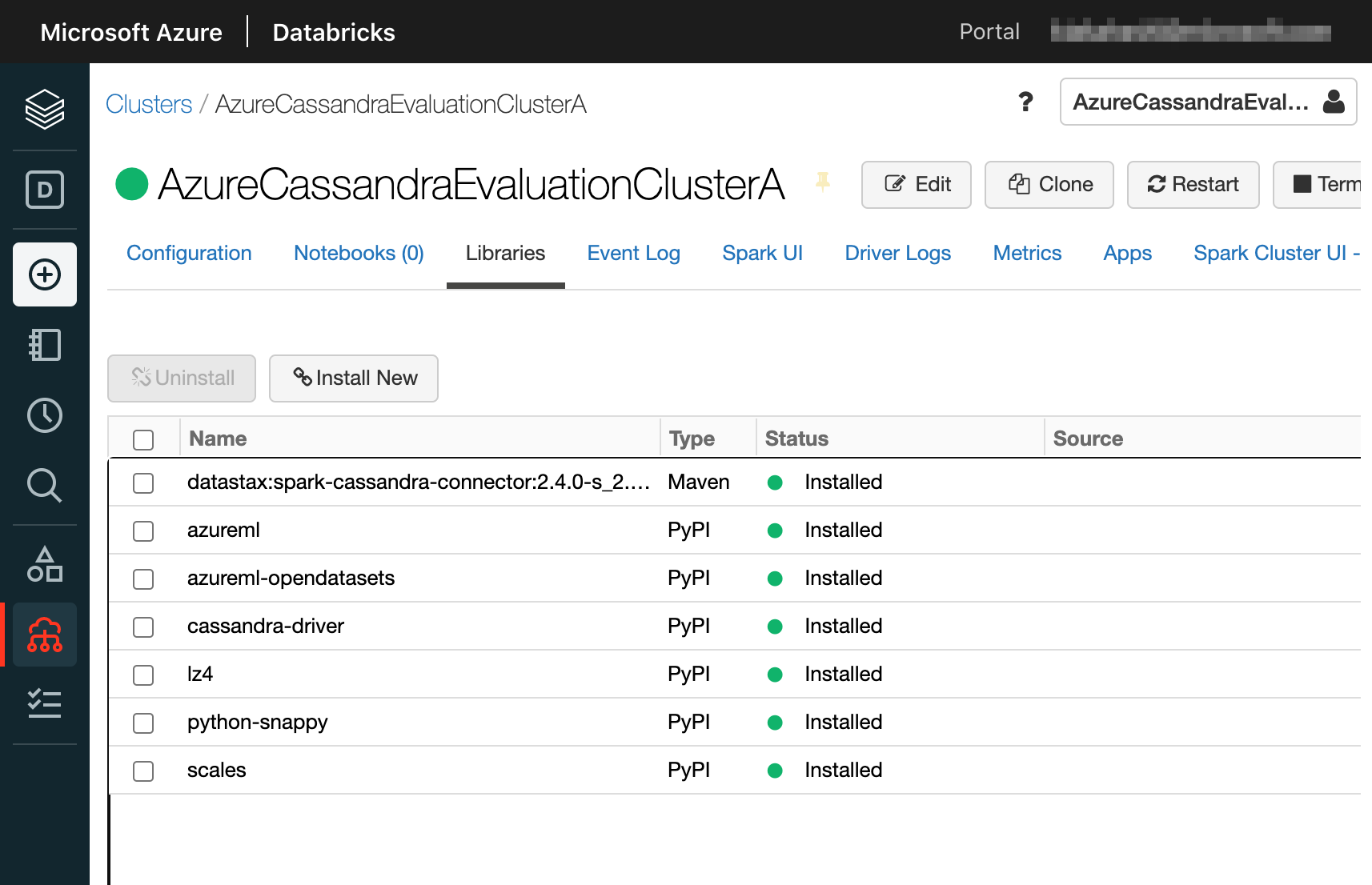
その他必要なライブラリをインストールする(任意)
他に使いたいライブラリがあれば同様にインストールすることができます。
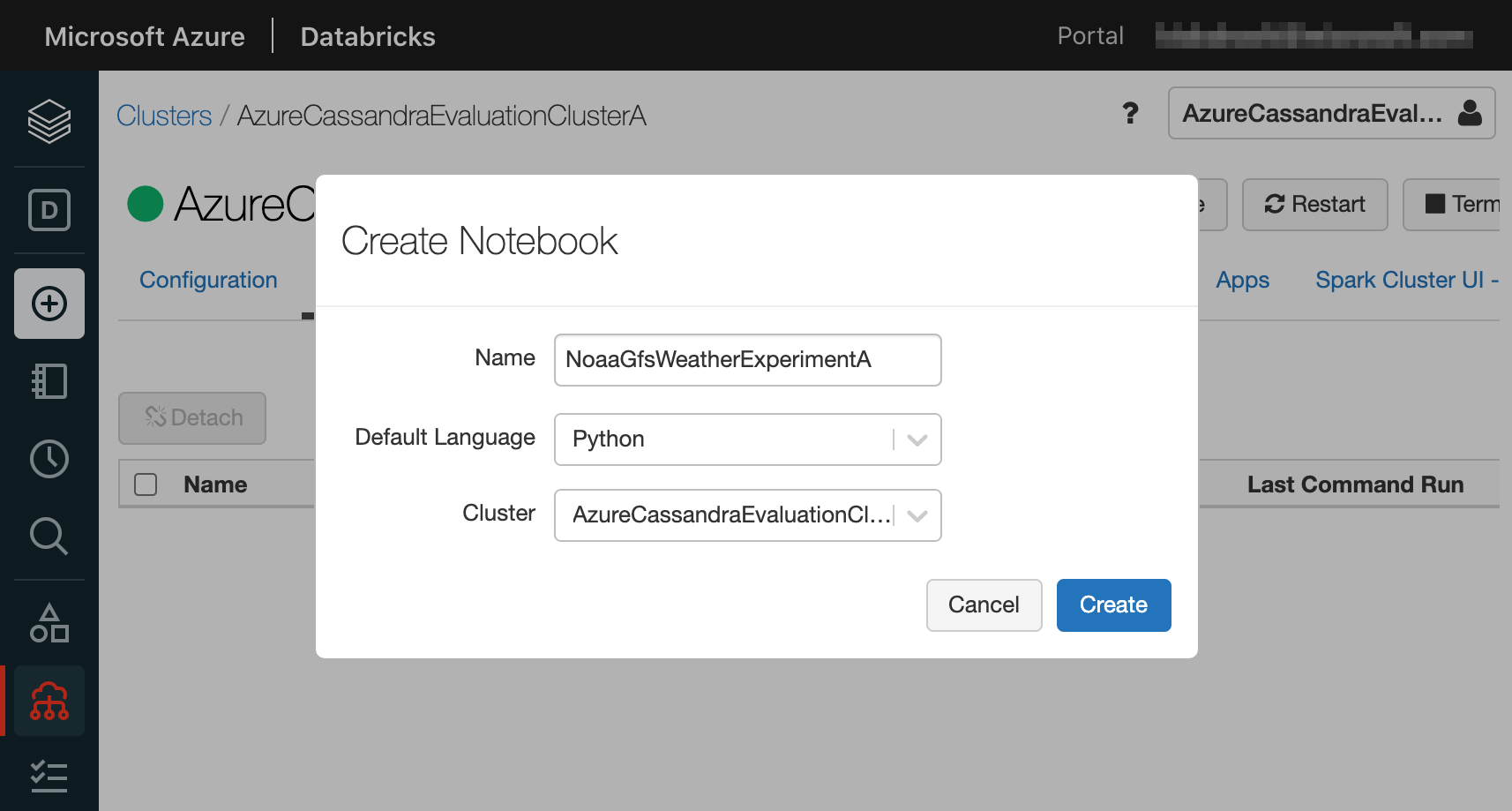
Notebook を作成する
サイドバーの + ボタンから、またはクラスターの Notebooks タブから Notebook を作成します。本記事では言語に Python を使用します。
コードを記述して実行する
以下のスクリーンショットのようにコードを記述して、各セルを実行していきます。
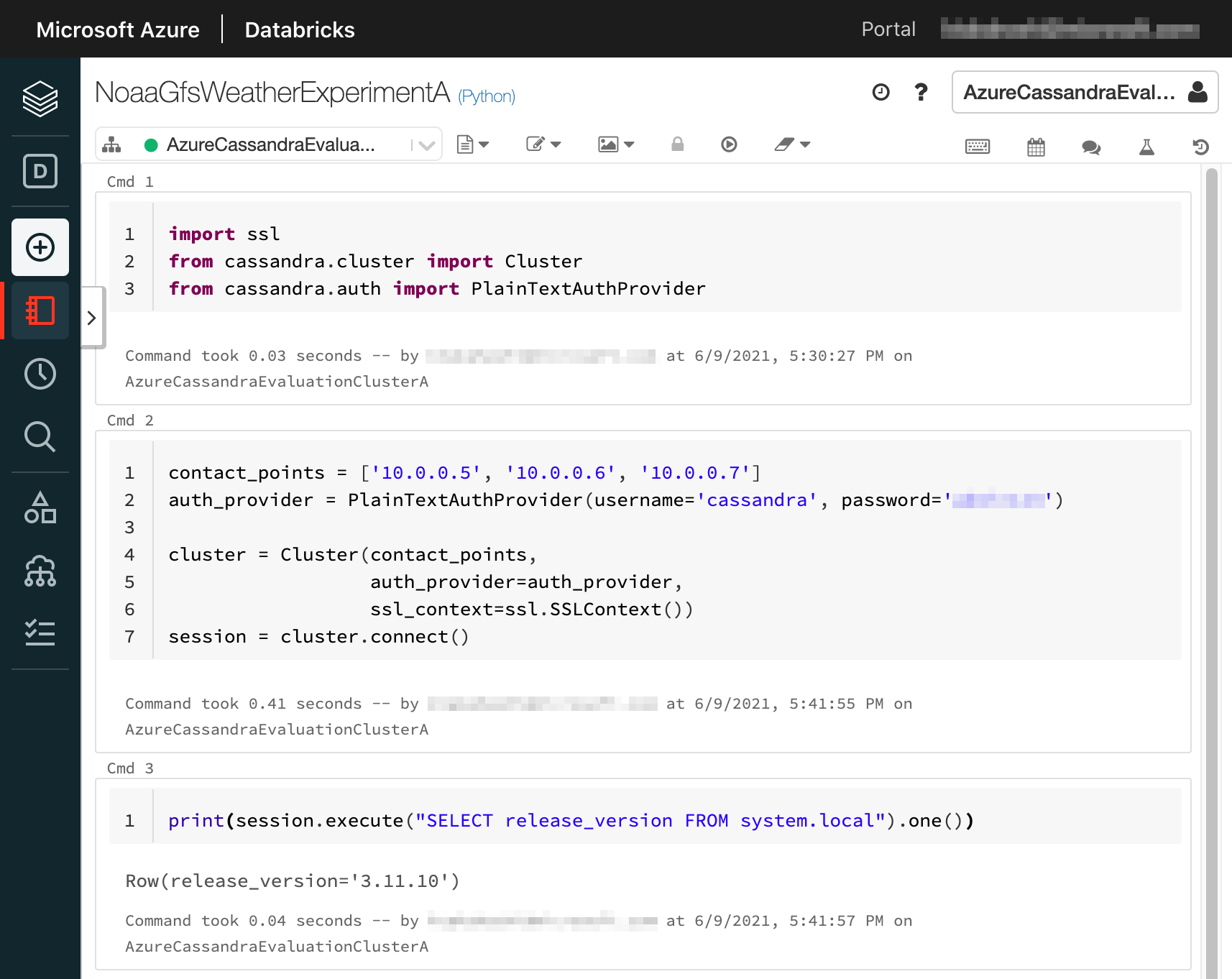
Cmd 3 で Azure Managed Instance for Apache Cassandra クラスターに対して CQL を実行し、 release_version を表示しています。
実行結果が正しいことを確認する
上記 release_version が正しいことを、仮想マシンから cqlsh 経由で同じ CQL を実行して検証します。
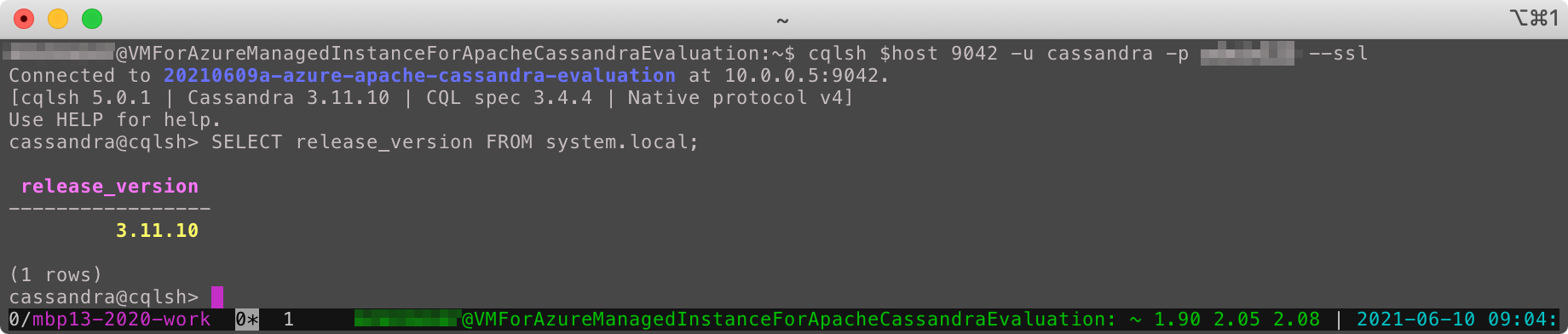
同じ値が取得できました。
まとめ
Azure Databricks クラスターから Azure Managed Instance for Apache Cassandra クラスターに接続して CQL を発行するための、 Azure Databricks クラスター構築手順を解説しました。今回は正しく接続できることをゴールとしており、より踏み込んだ利用方法については別途解説したいと思います。