Getting started with Azure Databricks
本記事では、Azure Databricks をデプロイする方法を解説します。 Azure Databricks のリソースを作成して Workspace を立ち上げることをゴールとします。
前提
- Microsoft Azure に利用可能なサブスクリプションを持っている
- Azure Portal で操作を行う
免責
- 筆者の環境は英語です。画面が日本語表示になっていない点、ご了承ください。
手順
リソースの作成を開始する
既存のリソースグループがある場合は、リソースグループから作成を行うこともできます。以下のスクリーンショットはその方式です。もちろん、リソースグループが無い状態からでもリソースは作成できます。
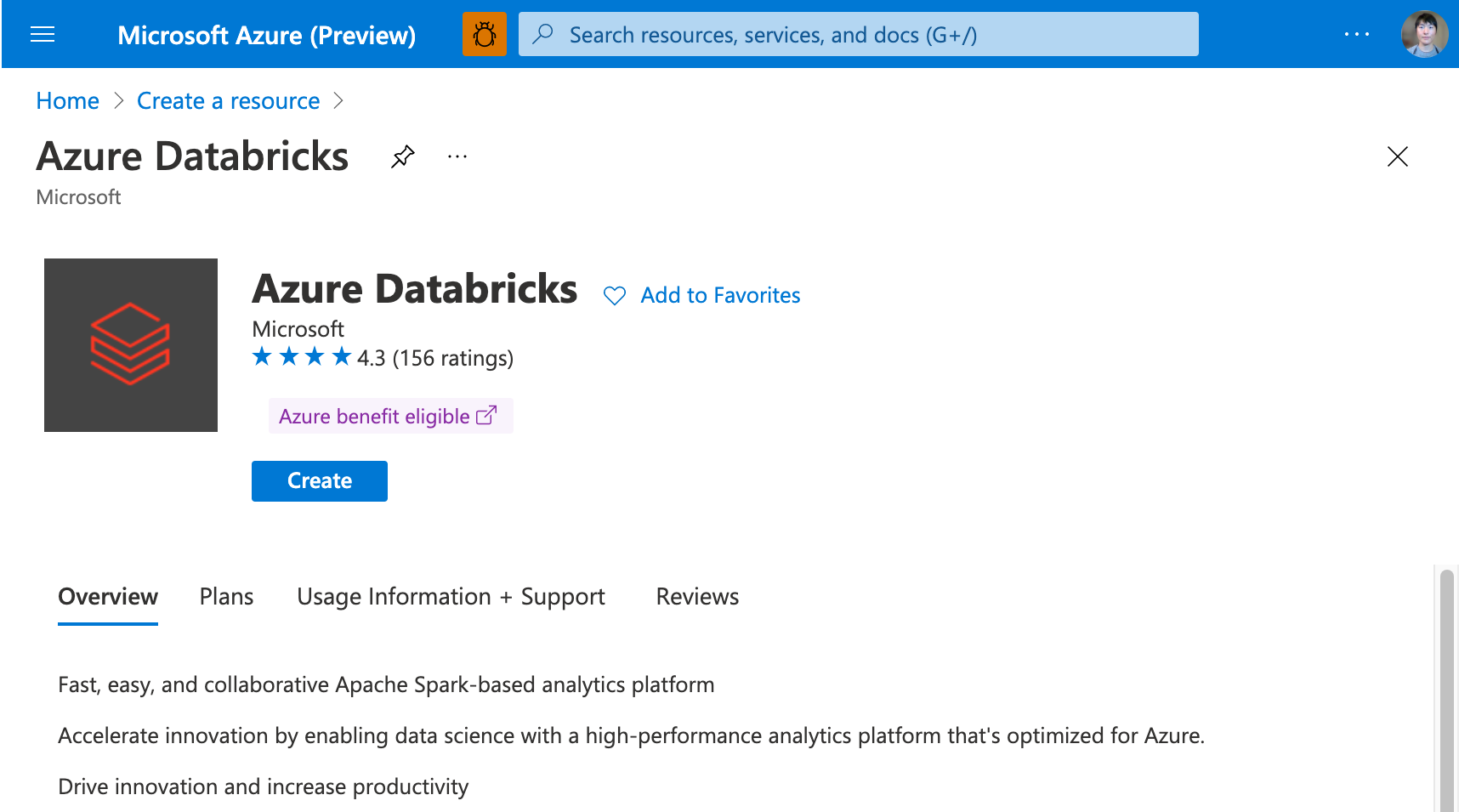
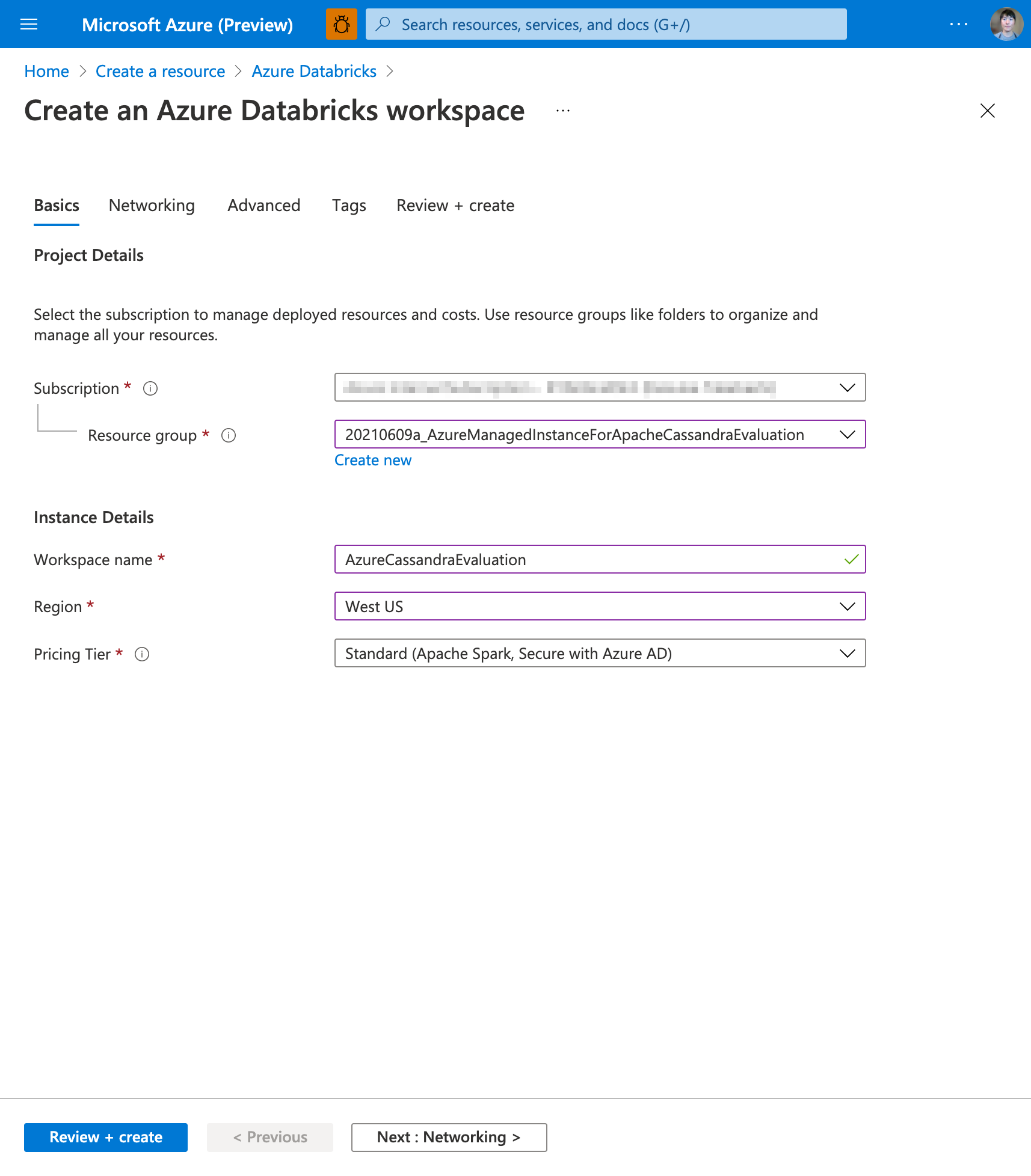
基本項目を入力する
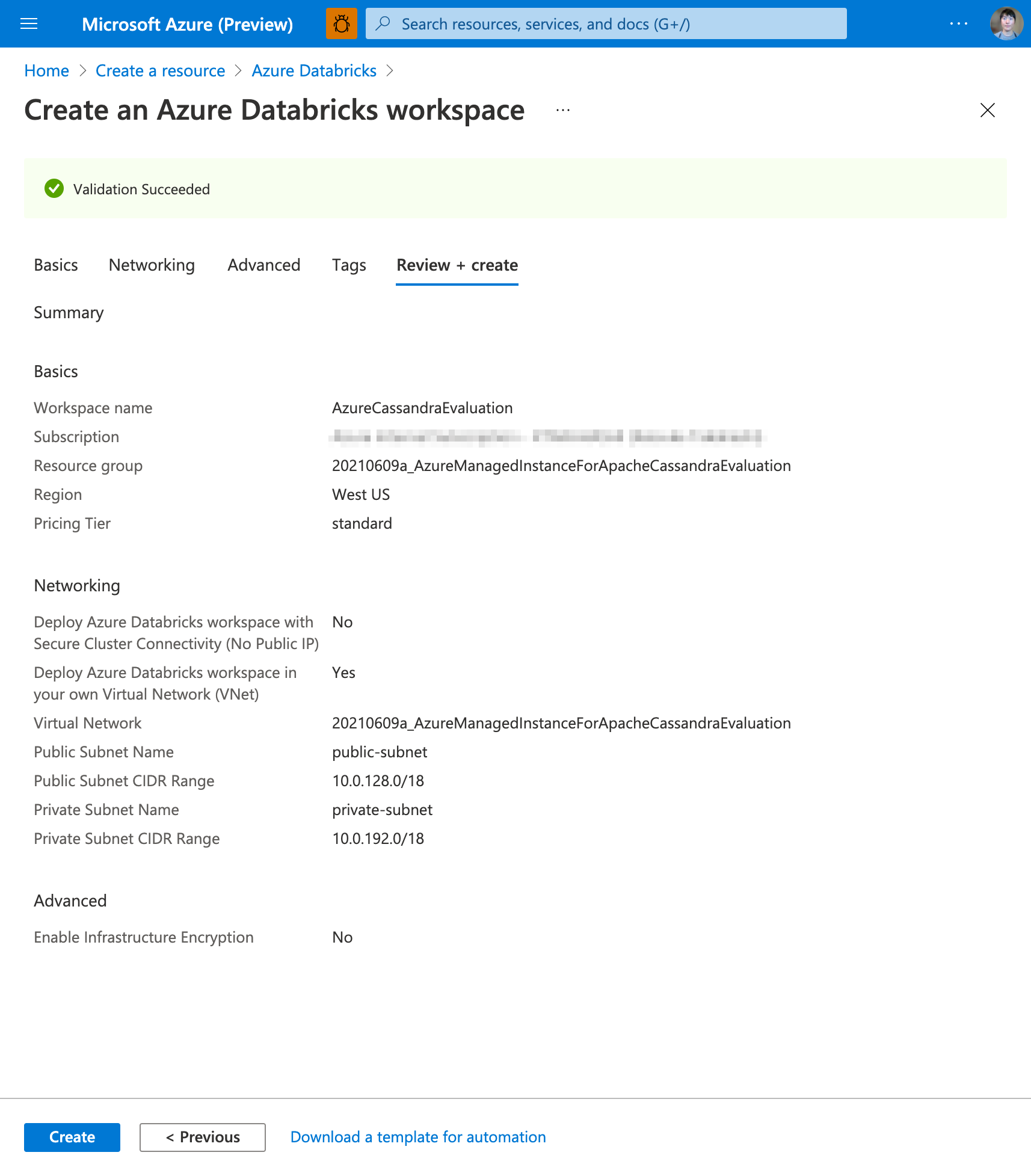
本記事では Get Started with Azure Managed Instance for Apache Cassandra で作成した Azure Managed Instance for Apache Cassandra クラスターと同じリソースグループに、 Azure Databricks を作成します。別の記事で、これらの連携について解説するためです。リージョンも同様に合わせてあります。
Azure Databricks 単体で利用する場合は、このような配慮は不要です。
ネットワークの項目を入力する
前項と同様に、 Virtual Network も Azure Managed Instance for Apache Cassandra と同じものを使用します。
既存の Virtual Network を利用する場合、 Public/Private Subnet CIDR Range は、それぞれ既存で使われている IPアドレス と衝突しないようにしてください。本記事では、既存で使われている IPアドレスが 10.0.0.x ですので、以下のスクリーンショットのように指定しました。
Azure Databricks 単体で利用する場合は、このような配慮は不要です。
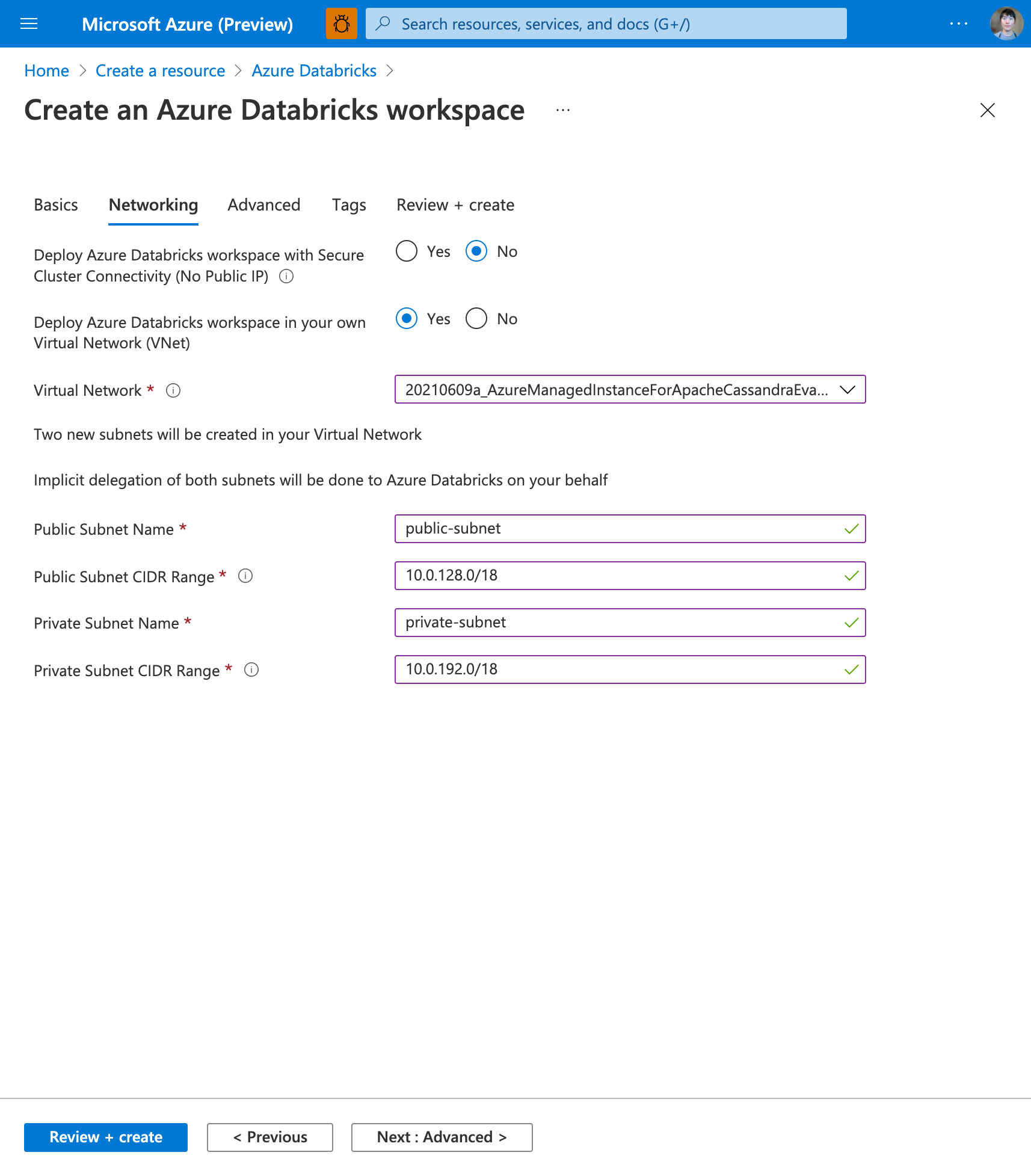
Public Subnet Name は public-subnet 、Private Subnet Name は private-subnet とします。初期状態では一見するとフォームに名前の値が既に入っているように見えますが、実際には単なるプレースホルダーですので(文字が微妙にグレーがかっている)、自分で入力する必要があります。
アドバンスドの項目を設定する(任意)
本記事では特に設定は行いません。
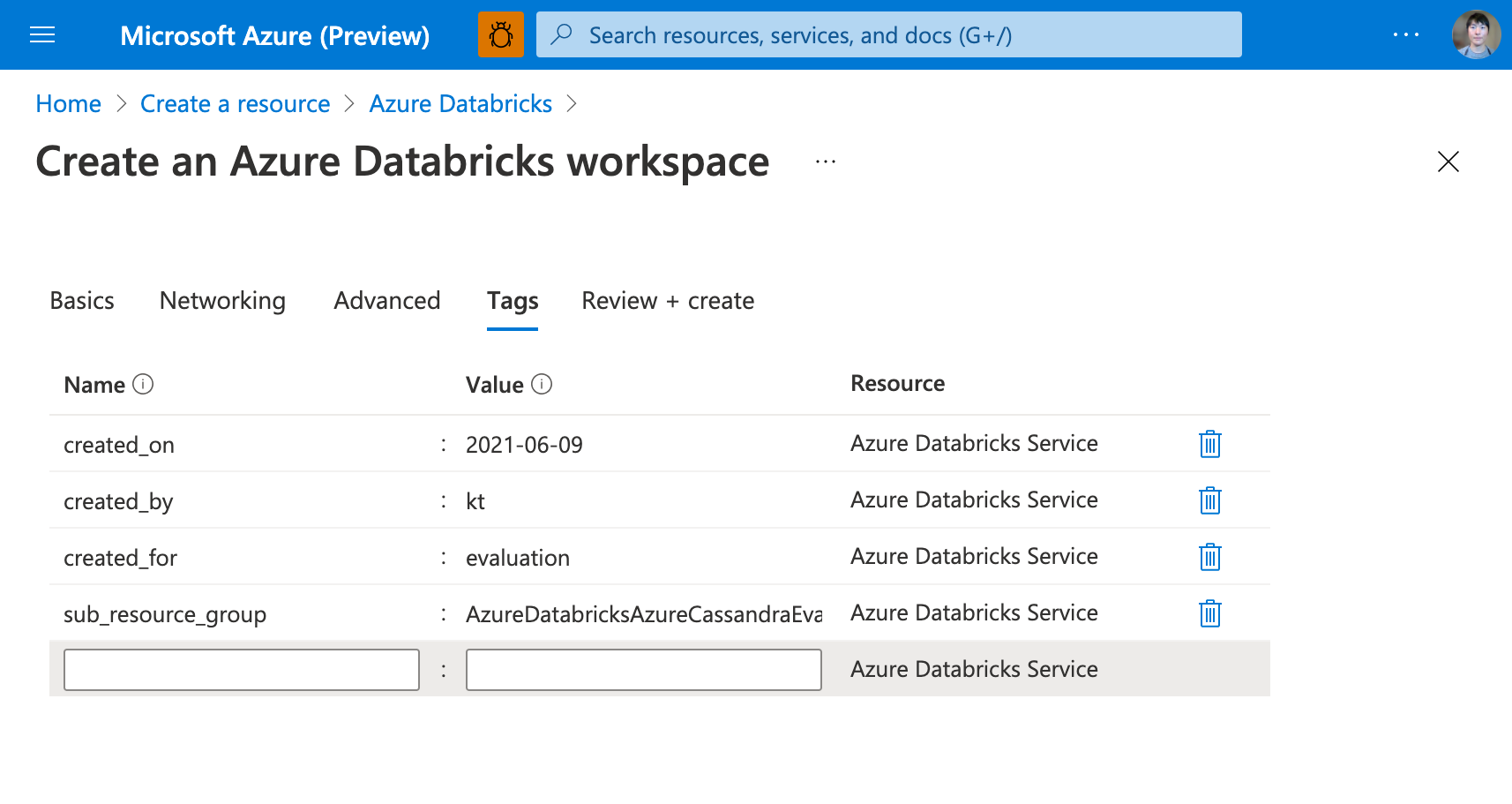
タグを入力する(任意)
筆者は独自にタグを付与しています。
レビューして作成する
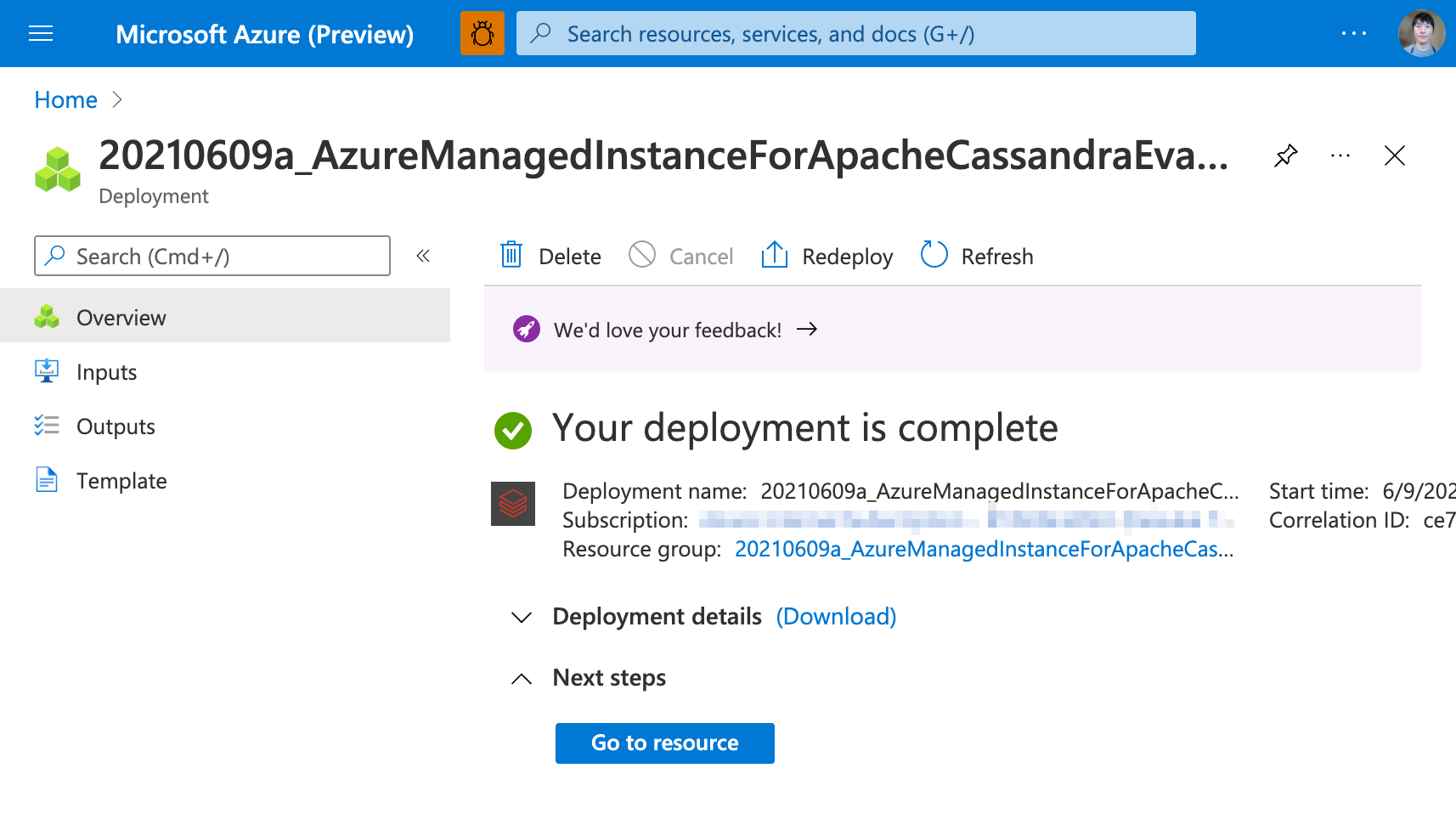
デプロイ完了
今回は約3分30秒でデプロイが完了しました。
リソースにアクセスする
Workspace を立ち上げる
まとめ
Azure Portal から Azure Databricks のリソースを作成する方法を解説しました。特に難しいことは無いと思いますし、オープンソース版のSparkをIaaSに構築するよりもはるかに簡単であると思います。 IPアドレス に関する基礎的な知識が少し必要ですので、不安な方には IPアドレス について勉強することをお勧めします。