Failure pattern on UDF with PySpark
上記記事では成功するアプローチで執筆していますが、本記事では、うまくいかなかったアプローチについて紹介したいと思います。
前提
- Transform and load data into Azure Managed Instance for Apache Cassandra on Azure Databricks in Python における UDF 関連のコードの意図を理解している
免責
- 筆者の環境やアプローチではうまくいかなかったのですが、何らかの工夫をすることで、本記事のアプローチを成功に導ける可能性はあり得ます。
解説
Insert data into Azure Managed Instance for Apache Cassandra on Azure Databricks in Python や Transform and load data into Azure Managed Instance for Apache Cassandra on Azure Databricks in Python では、 Cassandra テーブルに対する CQL 実行を、 Azure Databricks の Notebook 上でのイテレーションで実現していました。以下のような感じです。1 | dataCollect = df.rdd.toLocalIterator() |
このアプローチは成功しますが、パフォーマンスの観点でいうと全くメリットがありません。
当初は Spark のメリットを活かすために、以下のようなコードを書いていました。
1 | from pyspark.sql.types import UserDefinedType |
このコードの実行結果はエラーで、その内容は以下の通りです。
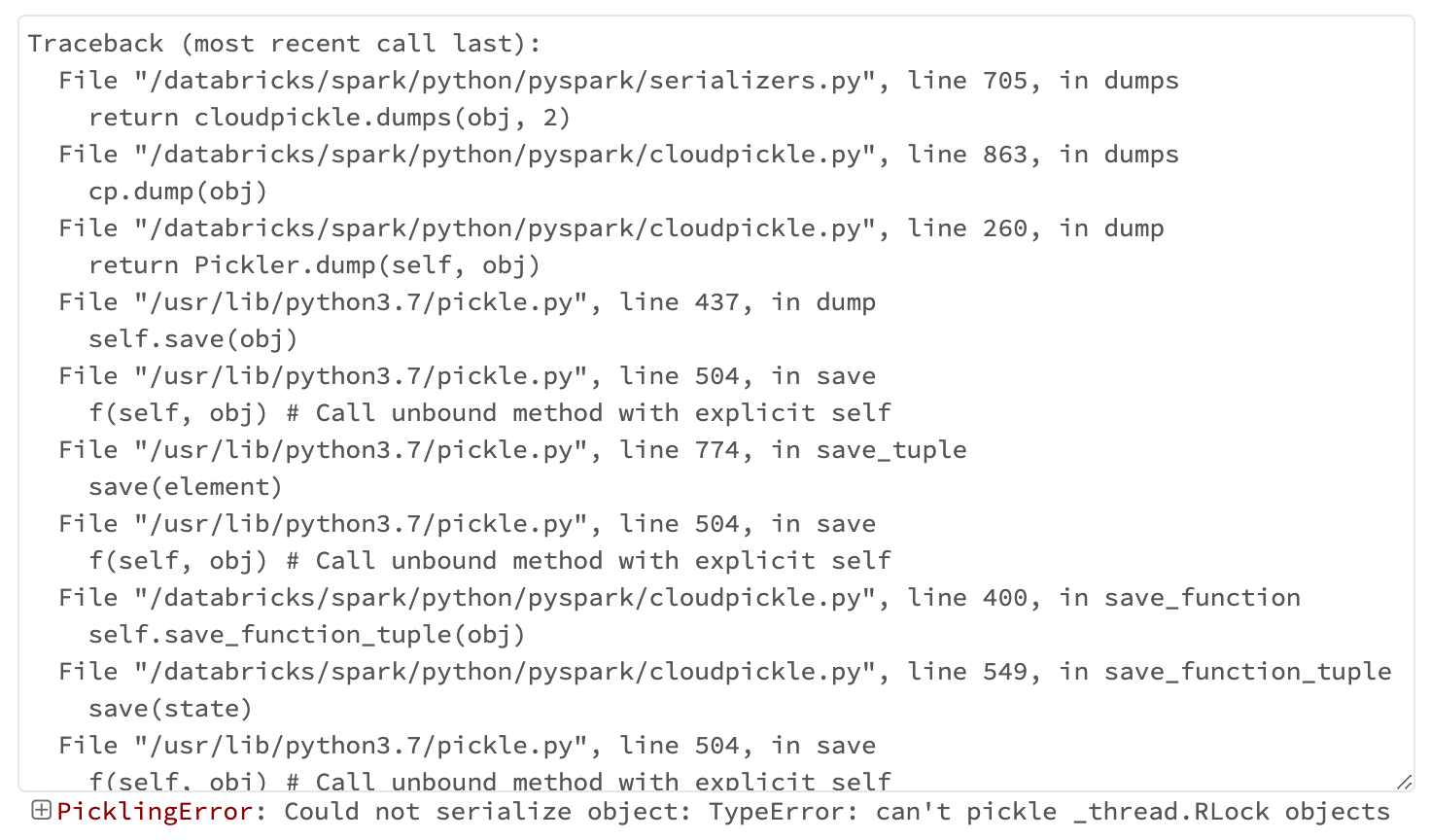
ちなみに、上記 UDF を使うアプローチ以外にも、 df.foreach() や df.rdd.map() で cassandra_session.execute(...) しようとした際にも、同じエラーが発生しています。
一方、 cassandra_session.execute(...) とは異なる、ありふれたコードをこれらで並行処理させようとすると、このようなエラーは出ずに Spark の処理が成功します。
このことから、 Spark に並行処理させるコードの中に、 Cassandra のセッション情報を含めることができないということが分かりました。
これは推測ですが、 cassandra_session はシングルトンになっていて、それを手元の Notebook の Python インタプリタから Spark に渡す際の PySpark によるシリアライズに失敗しているという状況なのだと思われます。
筆者は過去、別のインタプリタ言語で似たようなリモート処理を実装しようとして、やはりシリアライズに失敗した経験があります。もしかしたら、 Python ではなく Scala で記述することで、ブレークスルーできるかもしれません。
まとめ
Cassandra へのクエリを Spark で並行処理しようとして、うまくいかなかったパターンについてご紹介しました。
もしこれを改善できるアイディアがあれば、共有いただけると幸いです。