Use your own R packages as workspace ones on Azure Synapse Analytics Apache Spark Pool
自前の R パッケージを Azure Synapse Analytics Apache Spark プール のワークスペースパッケージとして使用する
本記事執筆時点ではパブリックプレビューですが、 Azure Synapse Analytics の Apache Spark プール では Python (PySpark), Scala, C# (.NET Spark), SQL だけでなく、R言語 (SparkR) も使用することができます。Apache Spark のバージョンとしては 3 以上で利用でき、本記事執筆時点で利用可能なバージョンは 3.1, 3.2, 3.3 (プレビュー) の 3 種類です。
Apache Spark プールで R のパッケージを利用する方法は 2 通りです。
前者の方が一時的なもので、後者の方が恒久的なものです。
なお、Python の場合は上記以外に Spark プール パッケージ という方法もあり、上記の中だと中間に位置します。
ノートブック セッション パッケージ の方が簡単です。ノートブックのセル内で
1 | install.packages("パッケージ名") |
と実行すれば、CRAN (Comprehensive R Archive Network) から依存関係も含めてパッケージをダウンロードし、コンパイル等してインストールしてくれます。フィーリングとしては Gentoo Linux の Portage に似ていると思います。また、上記以外にも devtools が利用可能です。
ただ、ノートブック セッション パッケージ はお手軽である反面、Spark のセッションが終了したらインストールしたパッケージも消えてしまうのがデメリットです。CRAN からのインストールの際にアーキテクチャに合ったバイナリをインストールしてくれれば早いのですが、そうではなく逐一コンパイルをするため、R パッケージのインストールには時間がかかります。
一方、ワークスペース パッケージ を利用すれば、Spark のセッションが終了しても、Spark クラスターにパッケージがインストールされたままとなります。こちらの方が良さそうに見えますが、デメリットとしては、依存関係が解決されないことです。
本記事では、前提となる環境構築手順を示した上で、R をワークスペース パッケージ として利用する際の失敗例と、問題の解決方法を示します。長くなるので、最初から解決方法を見ていただいても構いません。
なお、サンプルとして利用する R パッケージは C50 とします。
環境構築
Apache Spark プールにクラスターを作成します。
失敗例
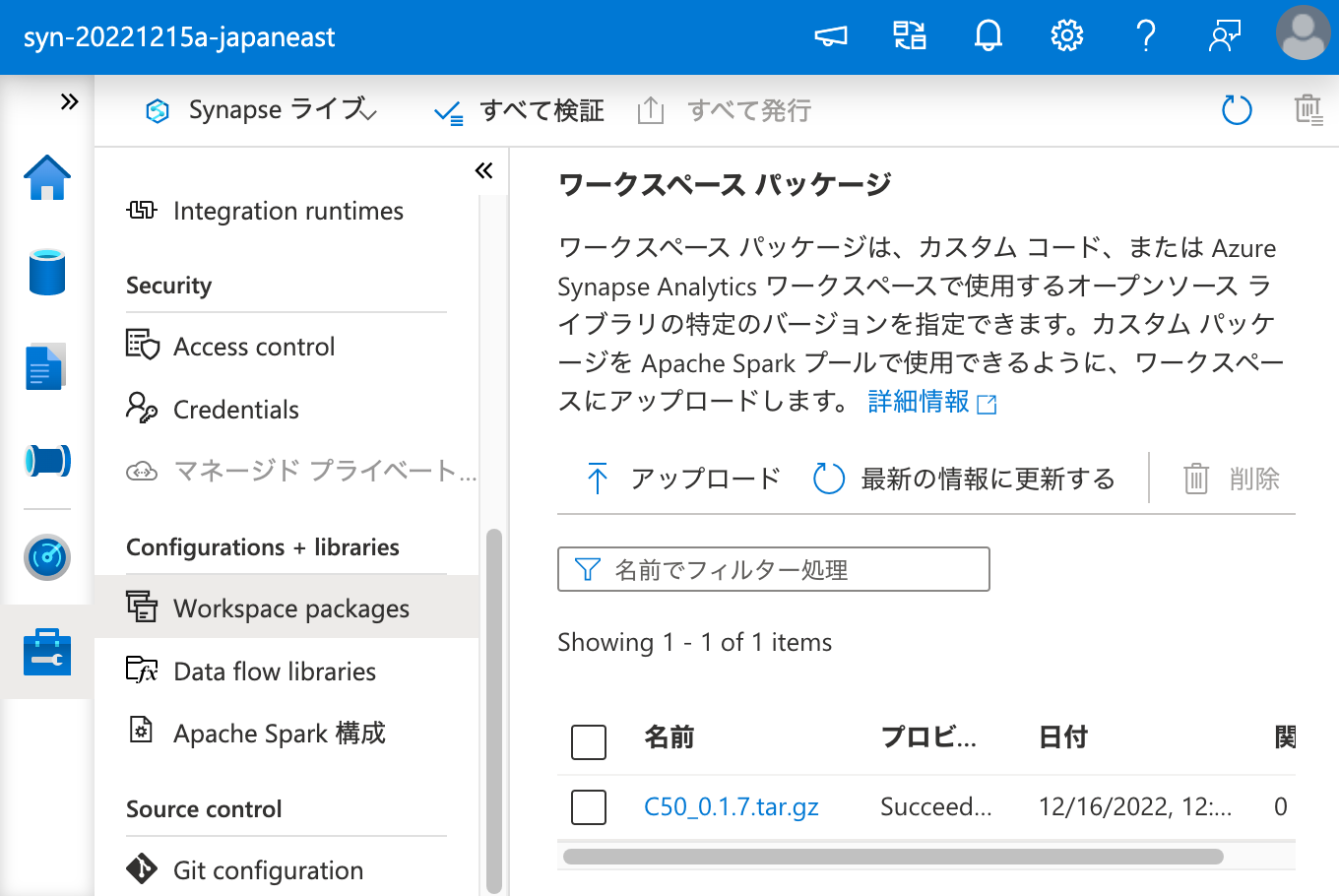
まず、ワークスペース パッケージに C50 を登録します。
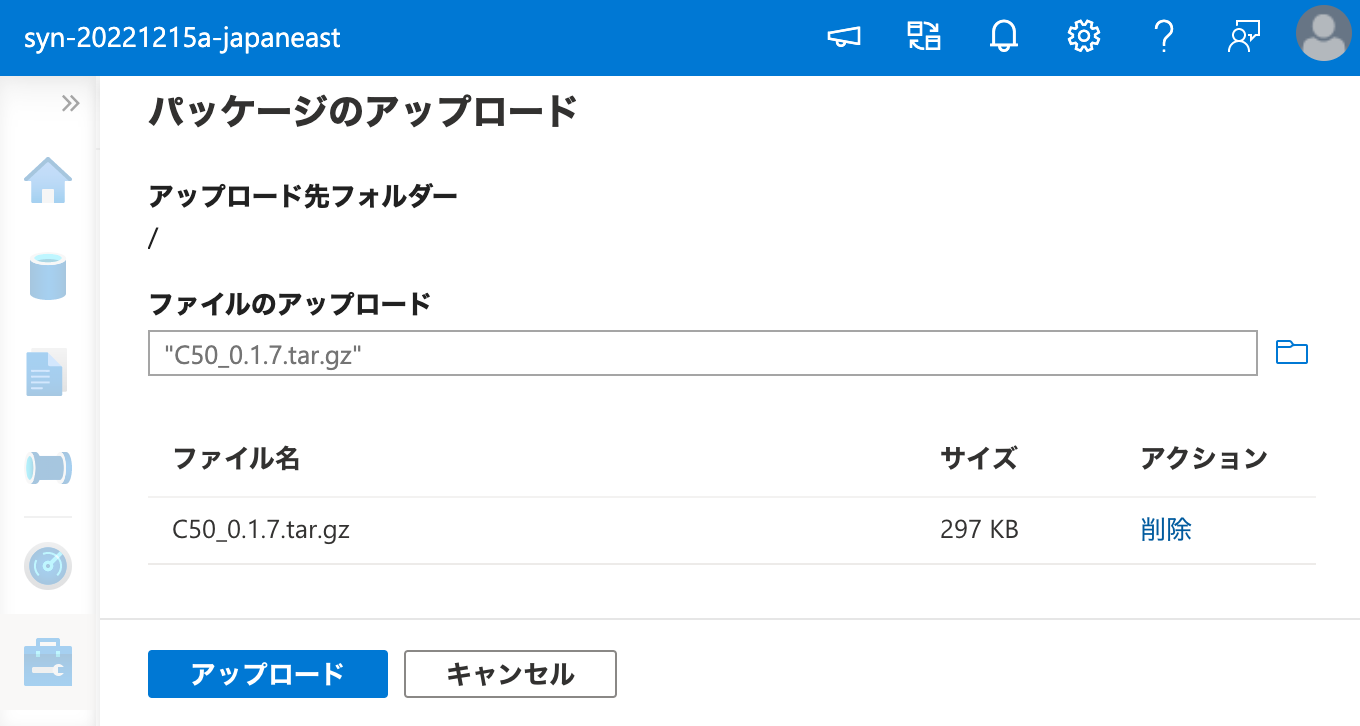
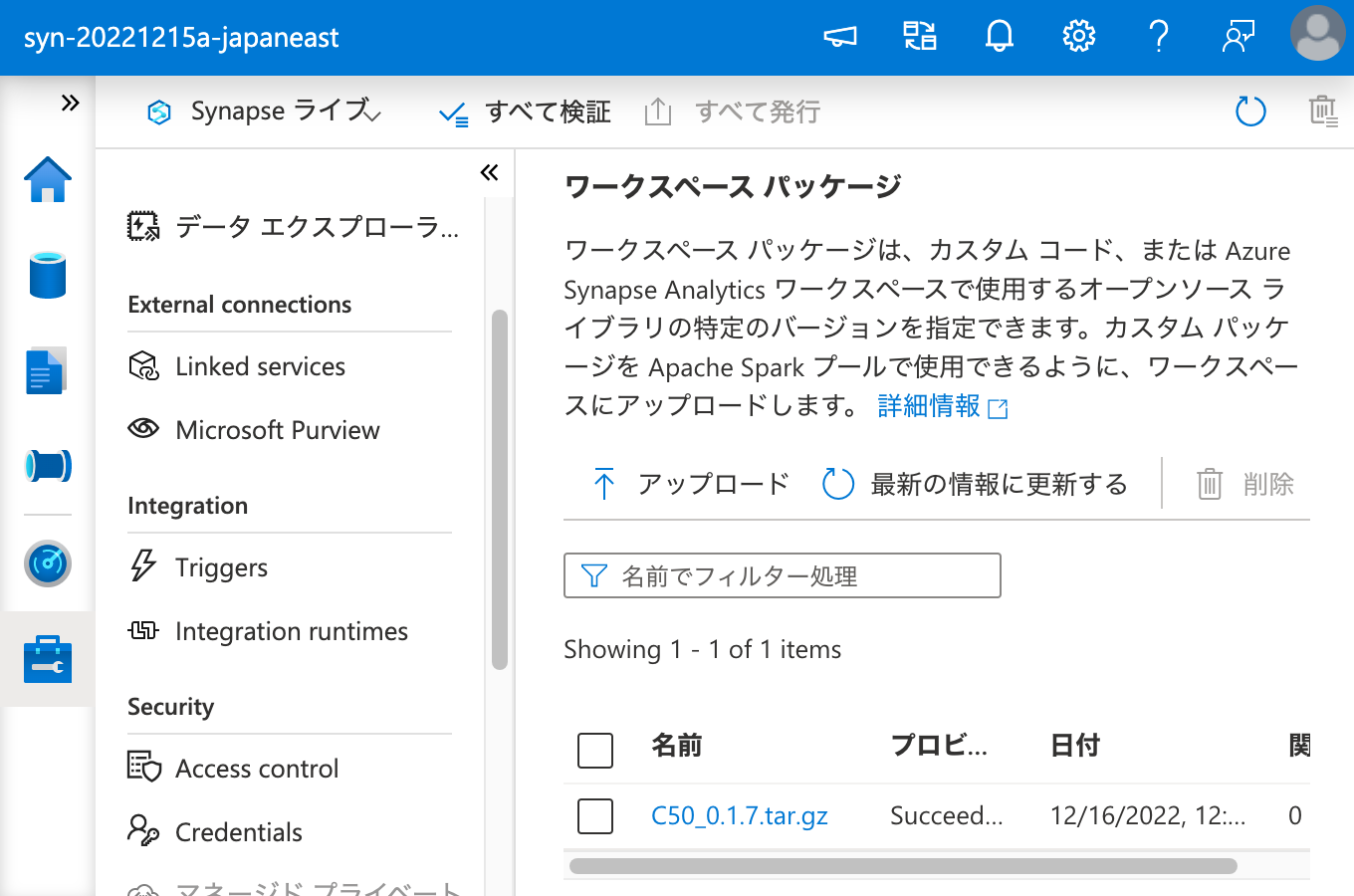
ワークスペース パッケージ として C50 を登録できたので、次は Apache Spark クラスターにこれをインストールするため、ワークスペース パッケージ から選択を行います。
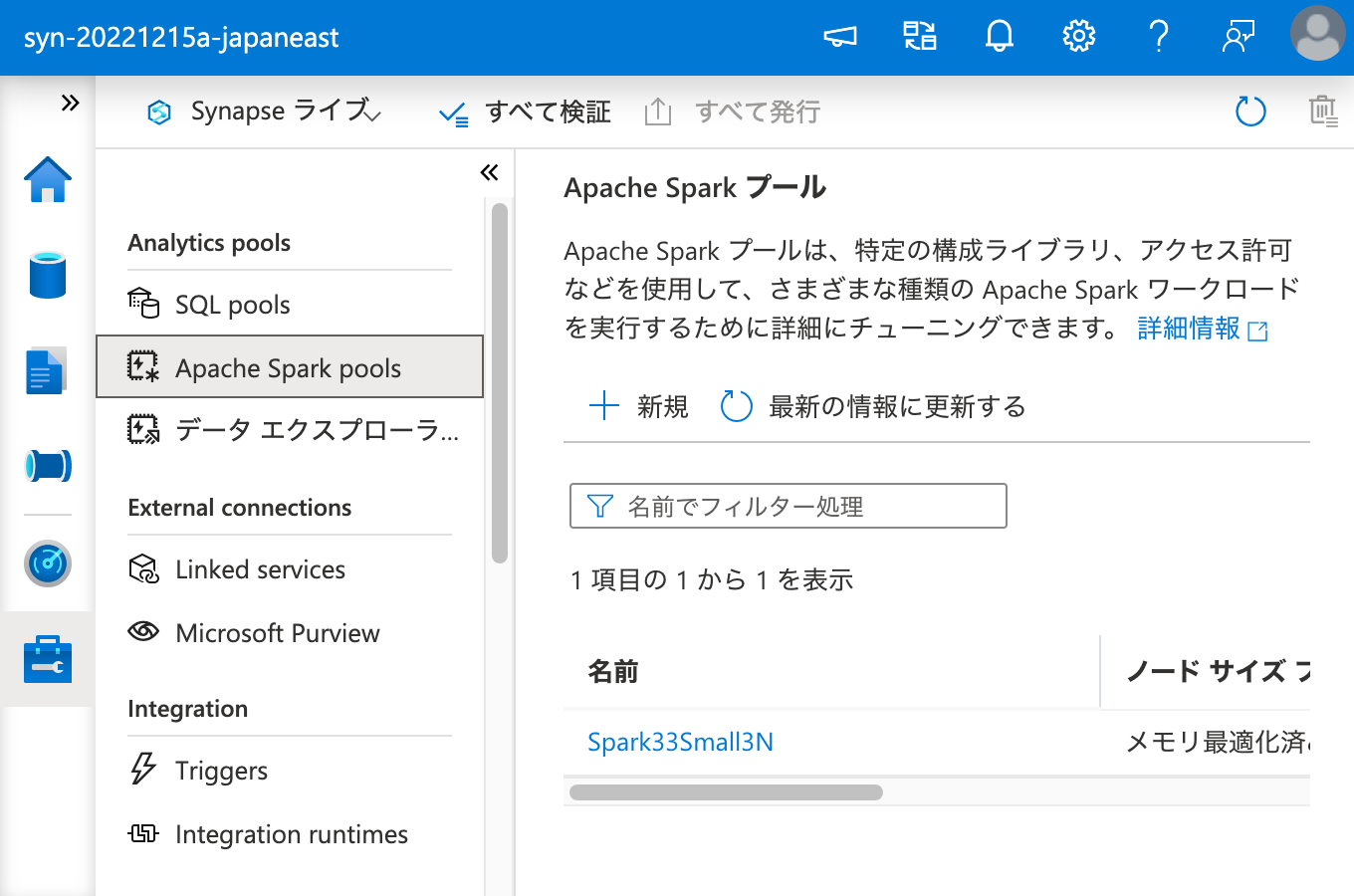
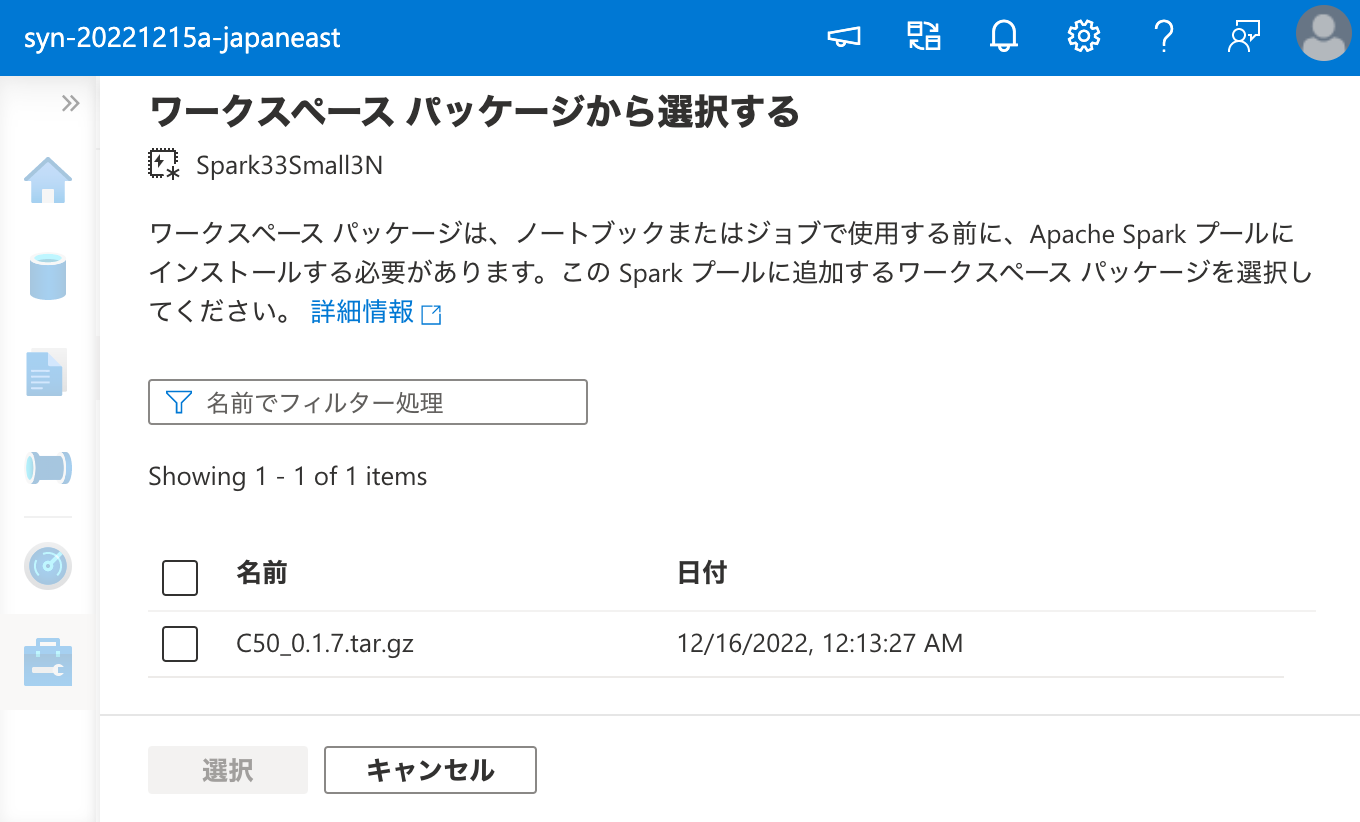
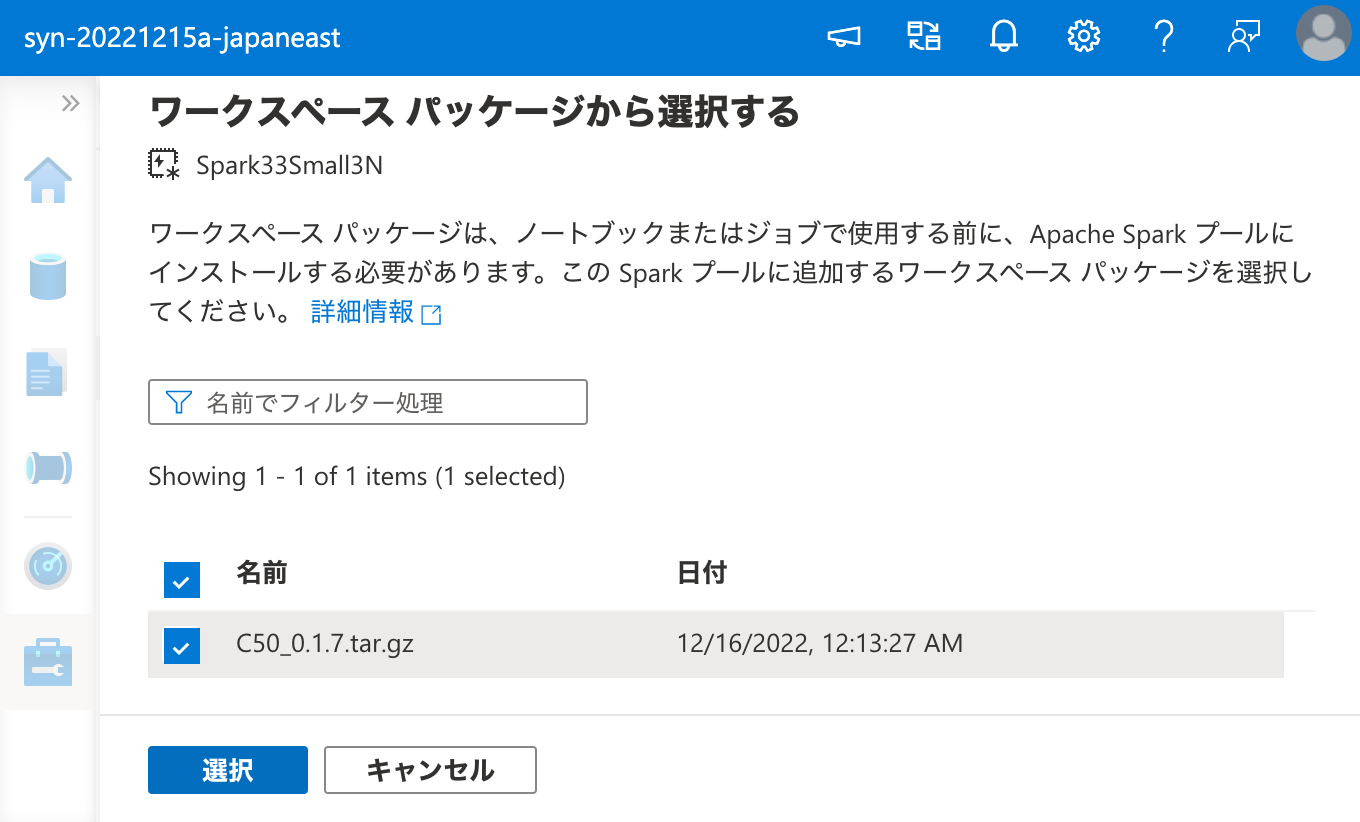
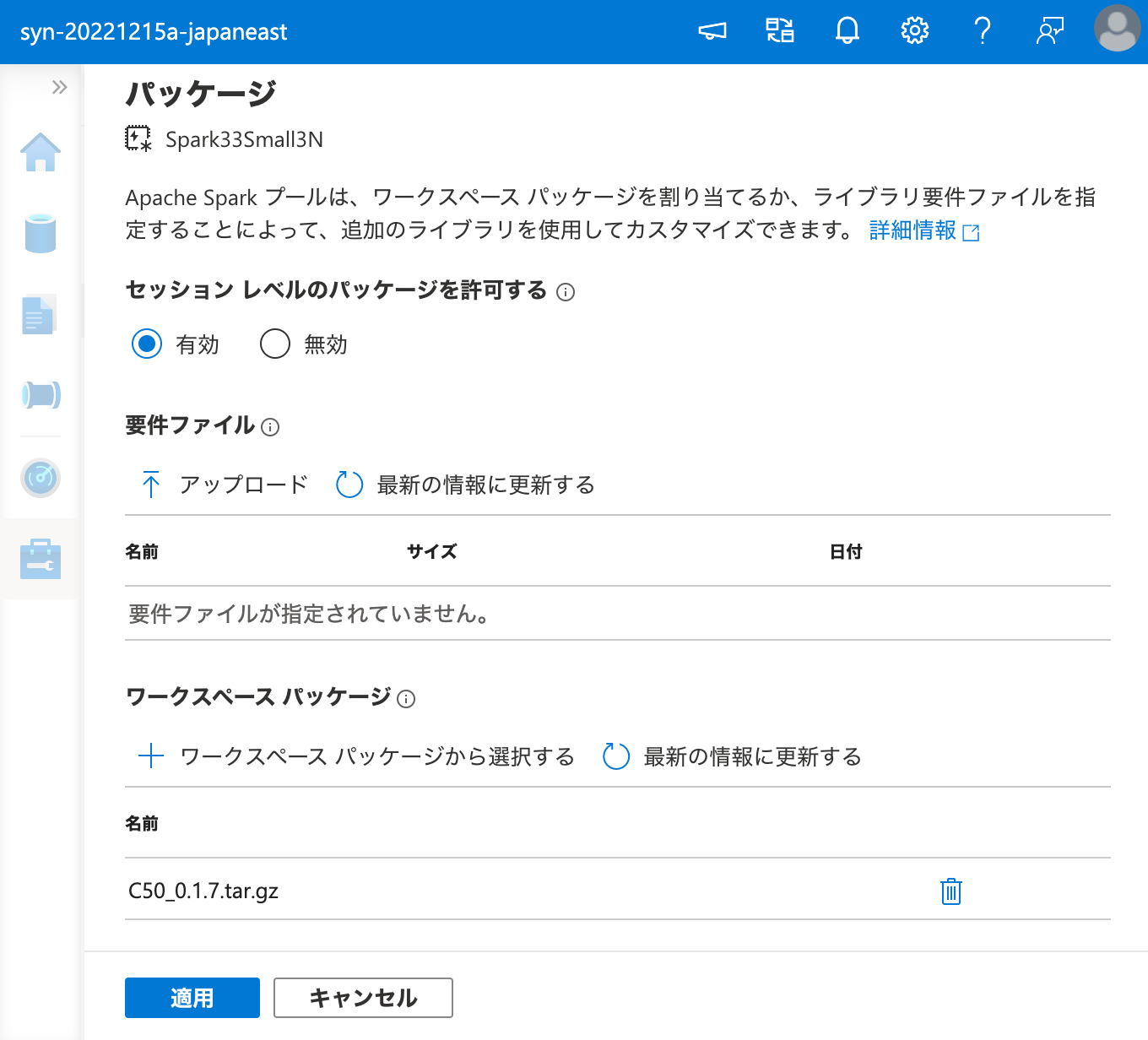
ここで、インストールには時間がかかるので、気長に待ちます。
そして、インストールは失敗します。エラーは以下の通りです。
1 | ProxyLivyApiAsyncError |
ノートブックを作成し、パッケージを呼び出してみます。
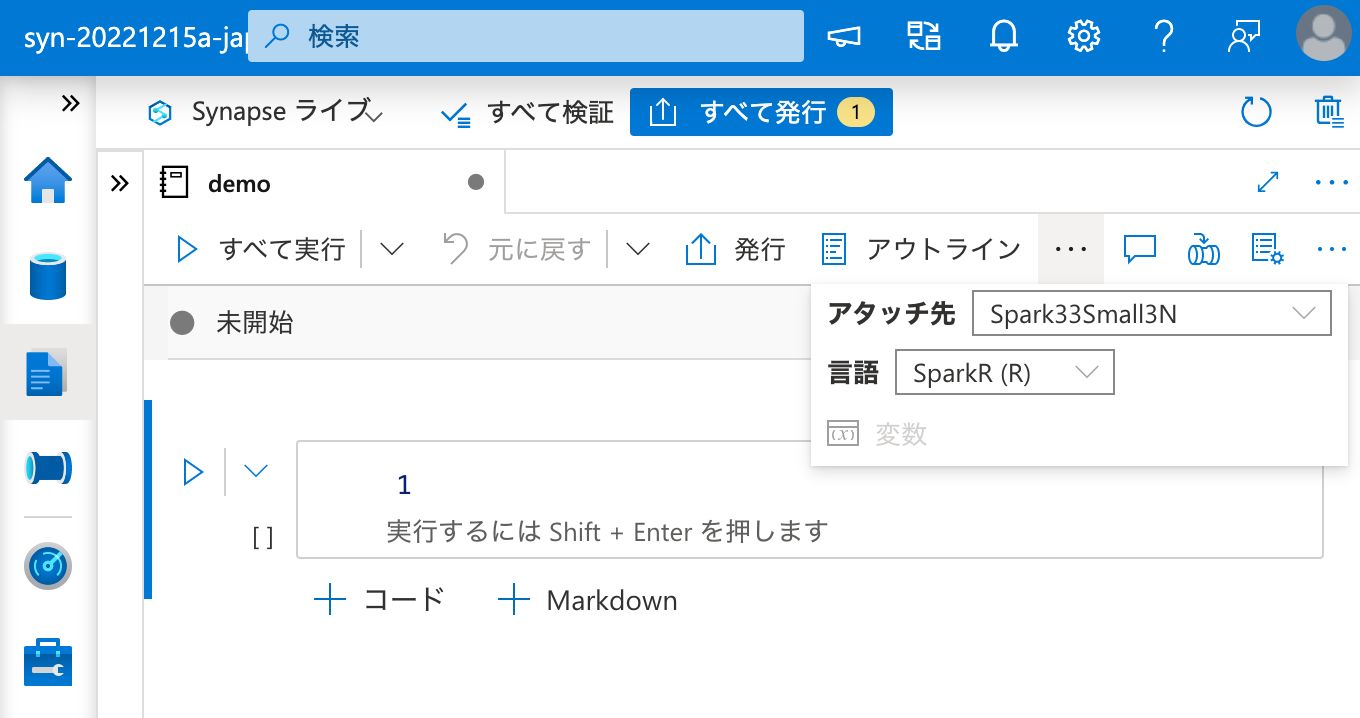
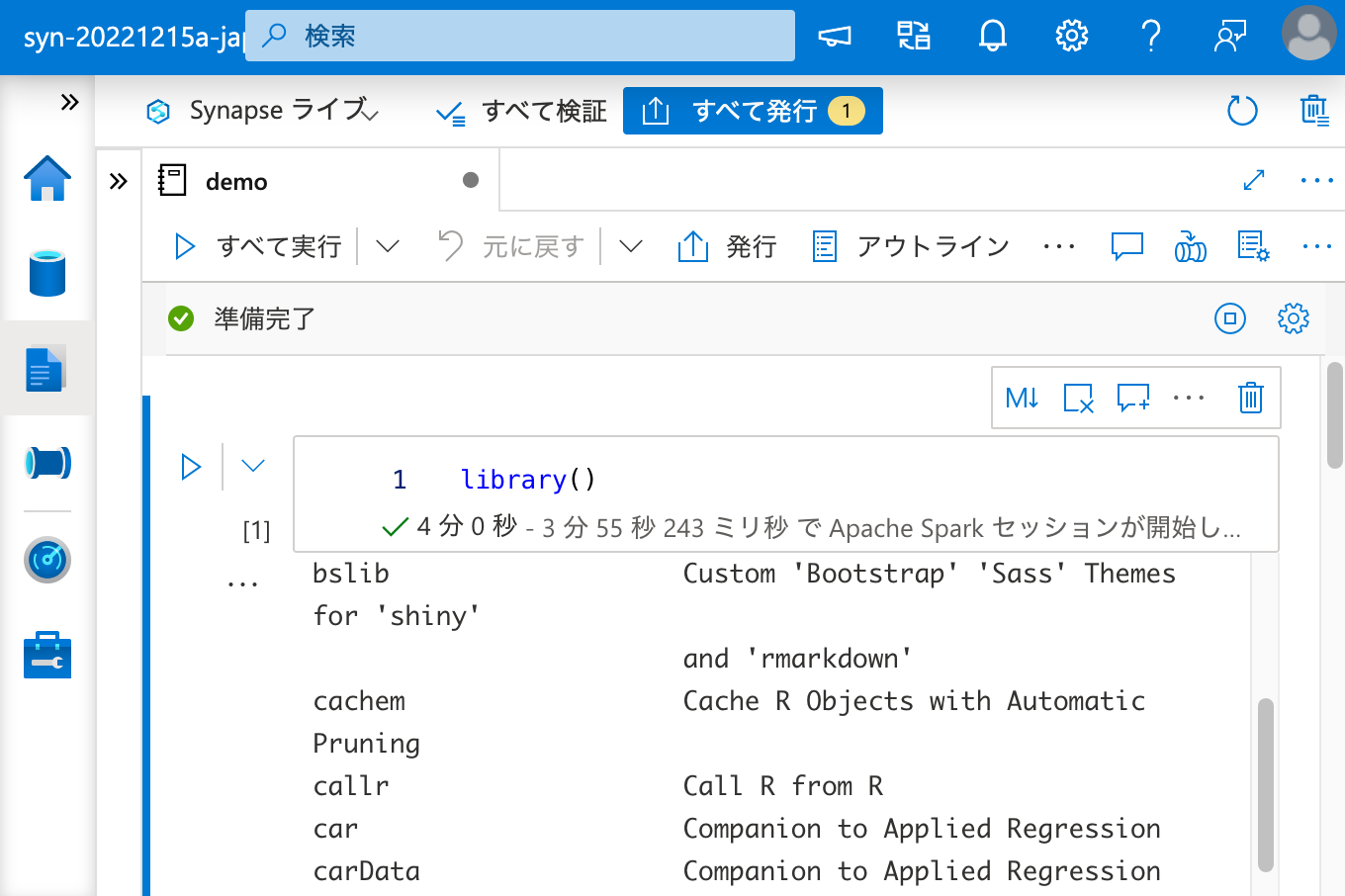
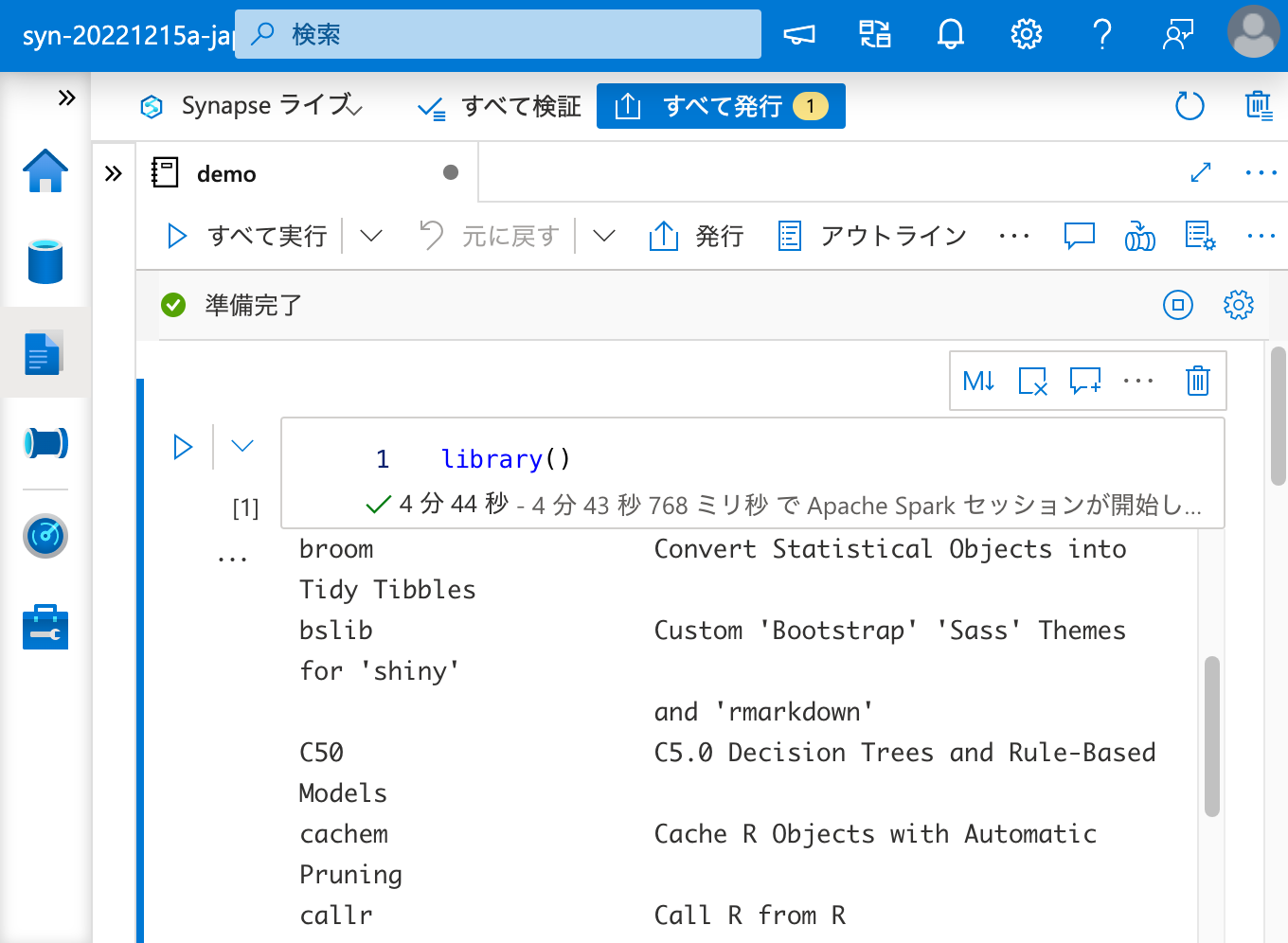
インストールされているパッケージの一覧に C50 はありません。
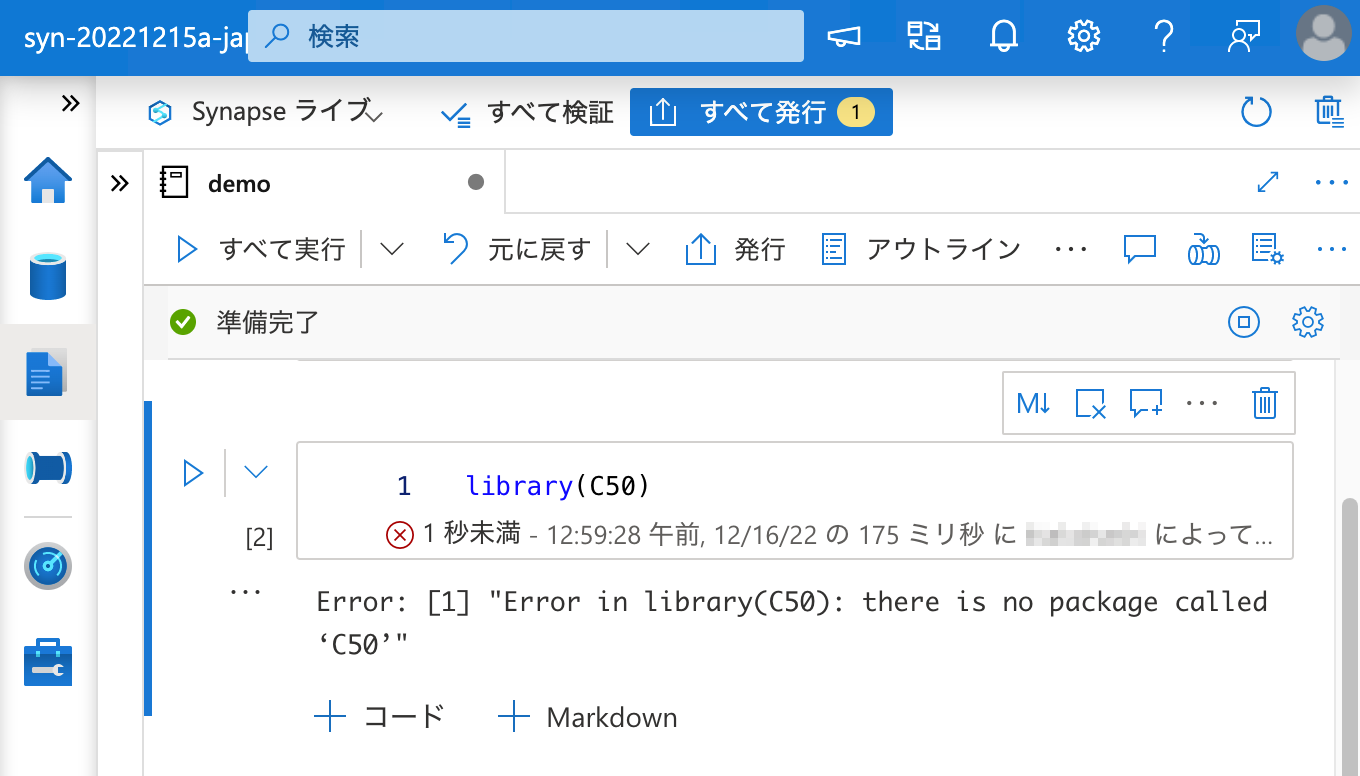
そして、パッケージを呼び出そうとするとエラーになりました。
解決方法
パッケージの依存関係を解決します。
ただ、依存関係を特定した上で、当該 Apache Spark クラスターのノードにどのパッケージがインストール済みか(※)、そしてそれぞれの依存パッケージのバージョンがインストールしようとしているパッケージの要件を満たしているか、確認するのは大変です。
※例えば Spark 3.3 ランタイムであれば、インストール済みのパッケージのリストは こちら にあります。
そこで、いったん ノートブック セッション パッケージ として依存関係を含めて目当てのパッケージをインストールし、そのログから ワークスペース パッケージ としてインストールする際に必要な依存パッケージを特定すると、誰でも簡単にこの問題を解決することができます。
その流れを以下に示します。
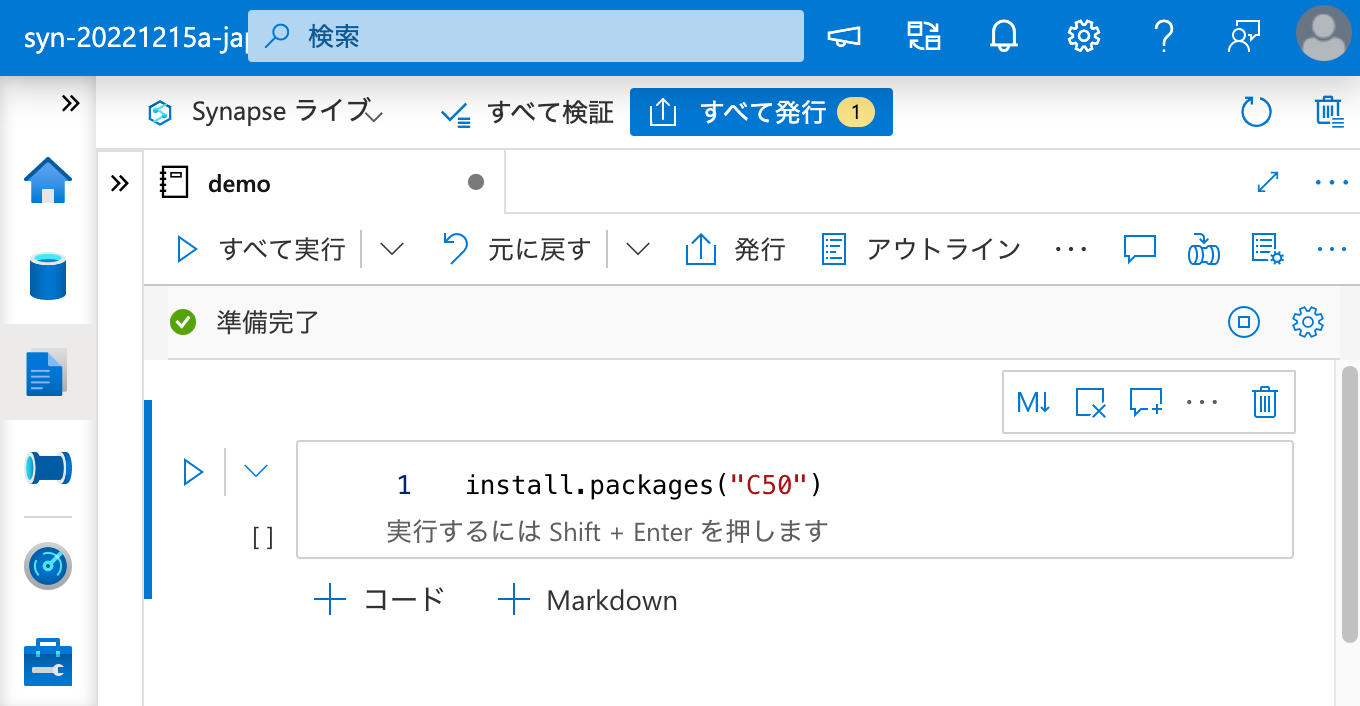
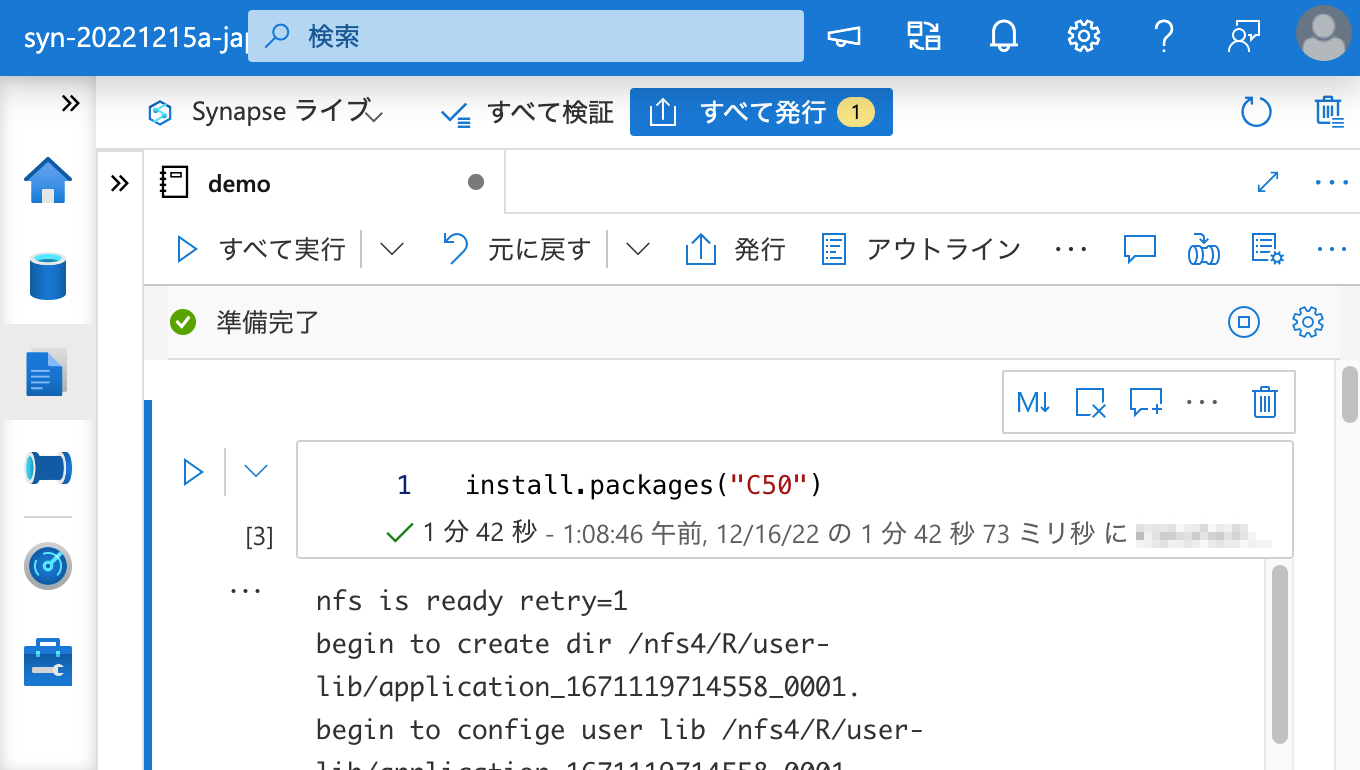
install.packages("C50") の出力には以下のような文字列が含まれています。
1 | also installing the dependencies ‘libcoin’, ‘mvtnorm’, ‘Formula’, ‘inum’, ‘partykit’, ‘Cubist’ |
そして、出力は
1 | * DONE (C50) |
という形でエラー無く DONE となっており、library() の結果に C50 は含まれていますし、
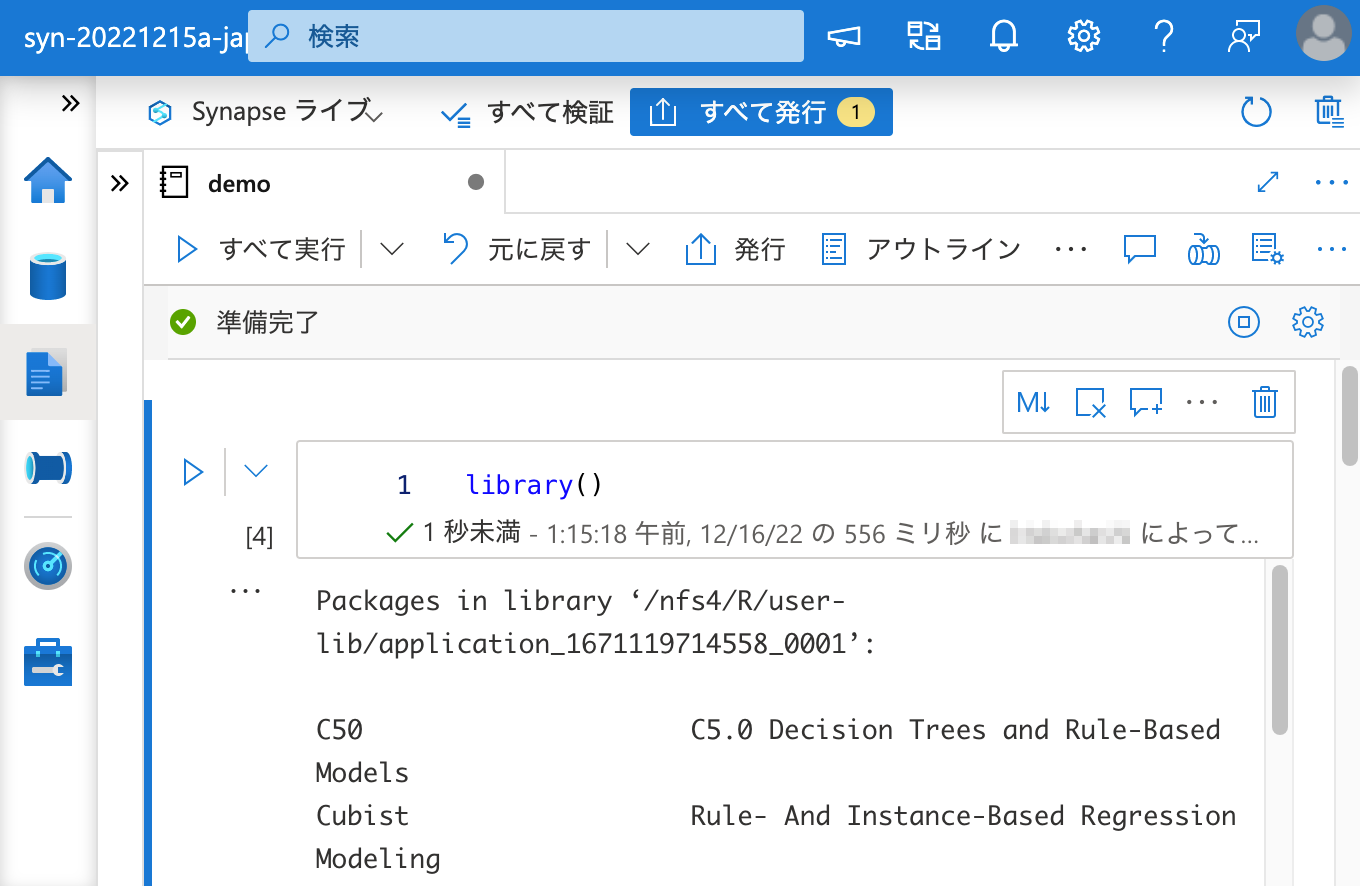
library(C50) でパッケージの読み込みもできます。
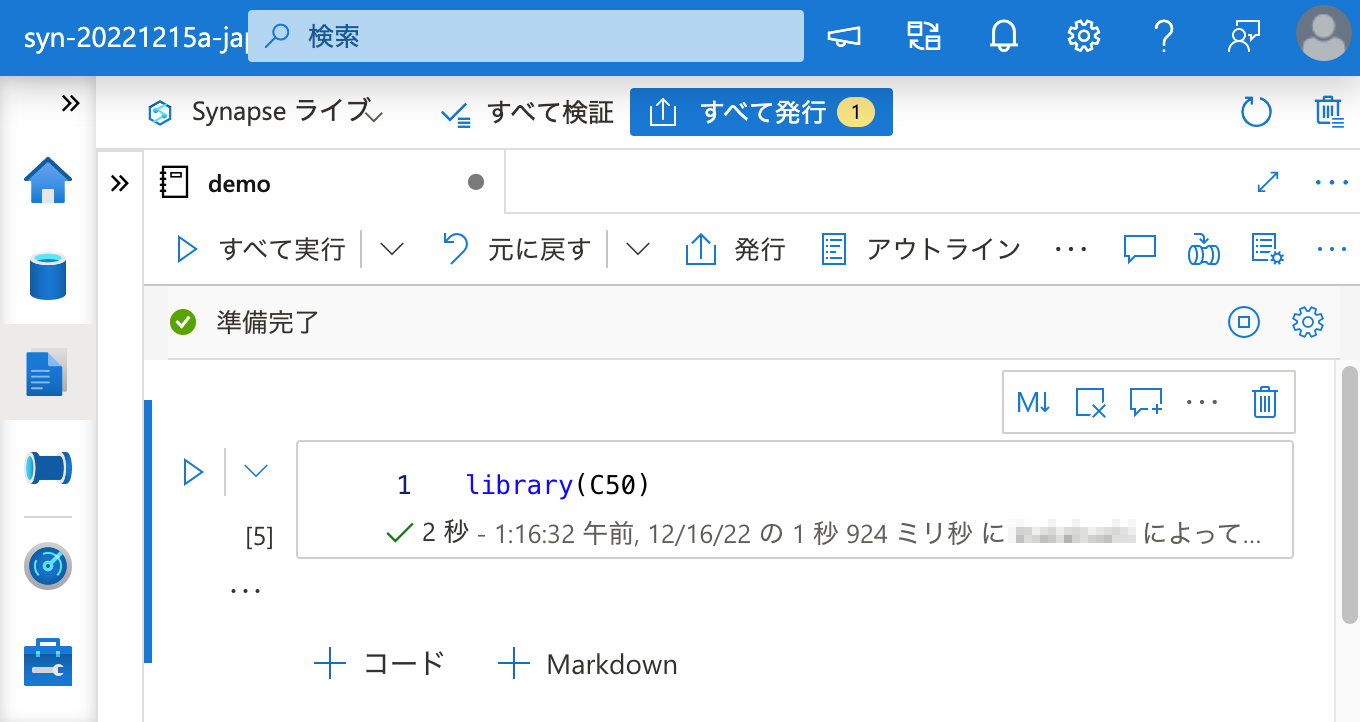
ワークスペース パッケージ としてパッケージをインストールする際に同時に必要となる依存パッケージは、上記の出力に含まれる .tar.gz の URI から wget 等でダウンロードしてくれば良いのです。
そして、Apache Spark プールのクラスターに、ワークスペース パッケージ からインストールを行います。
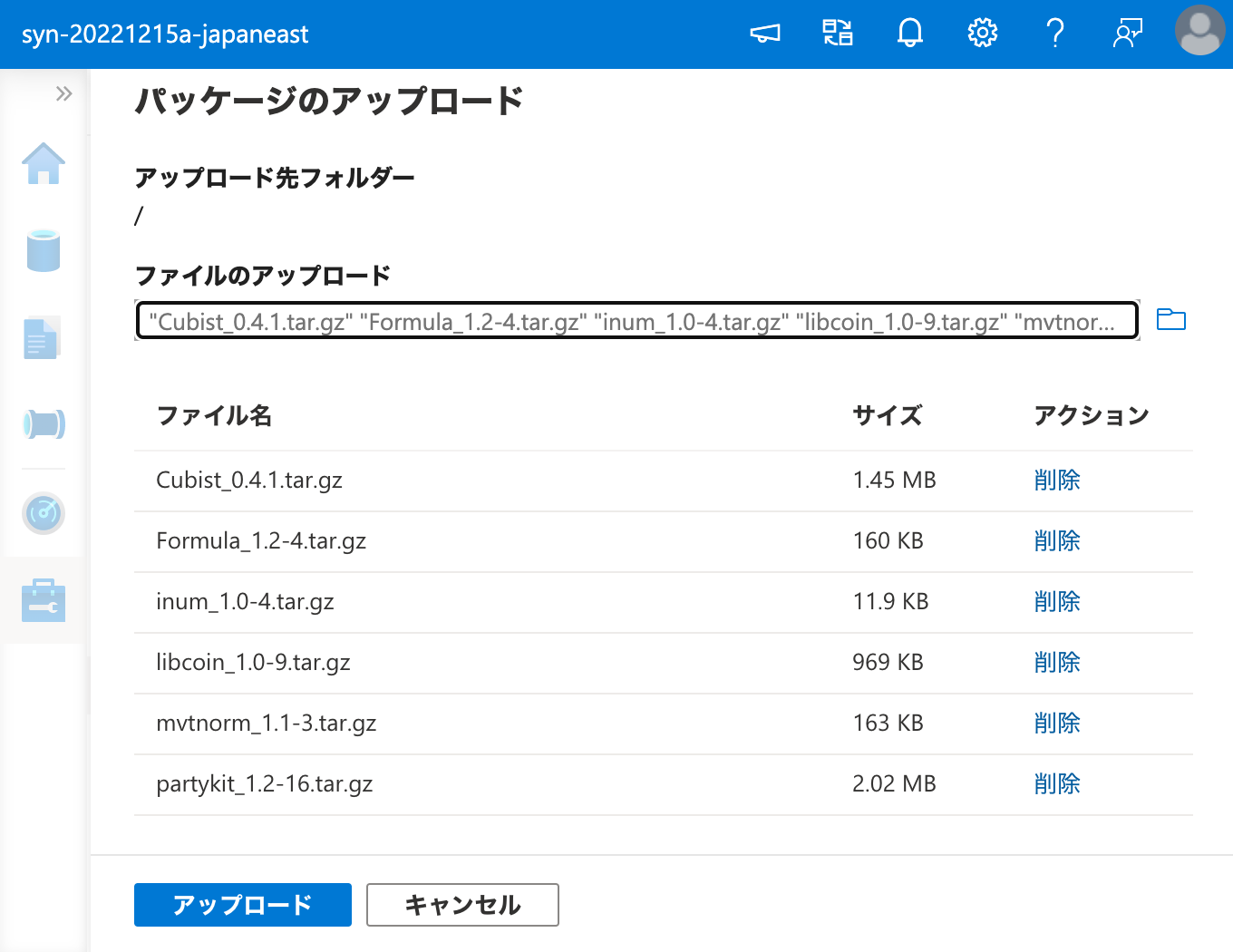
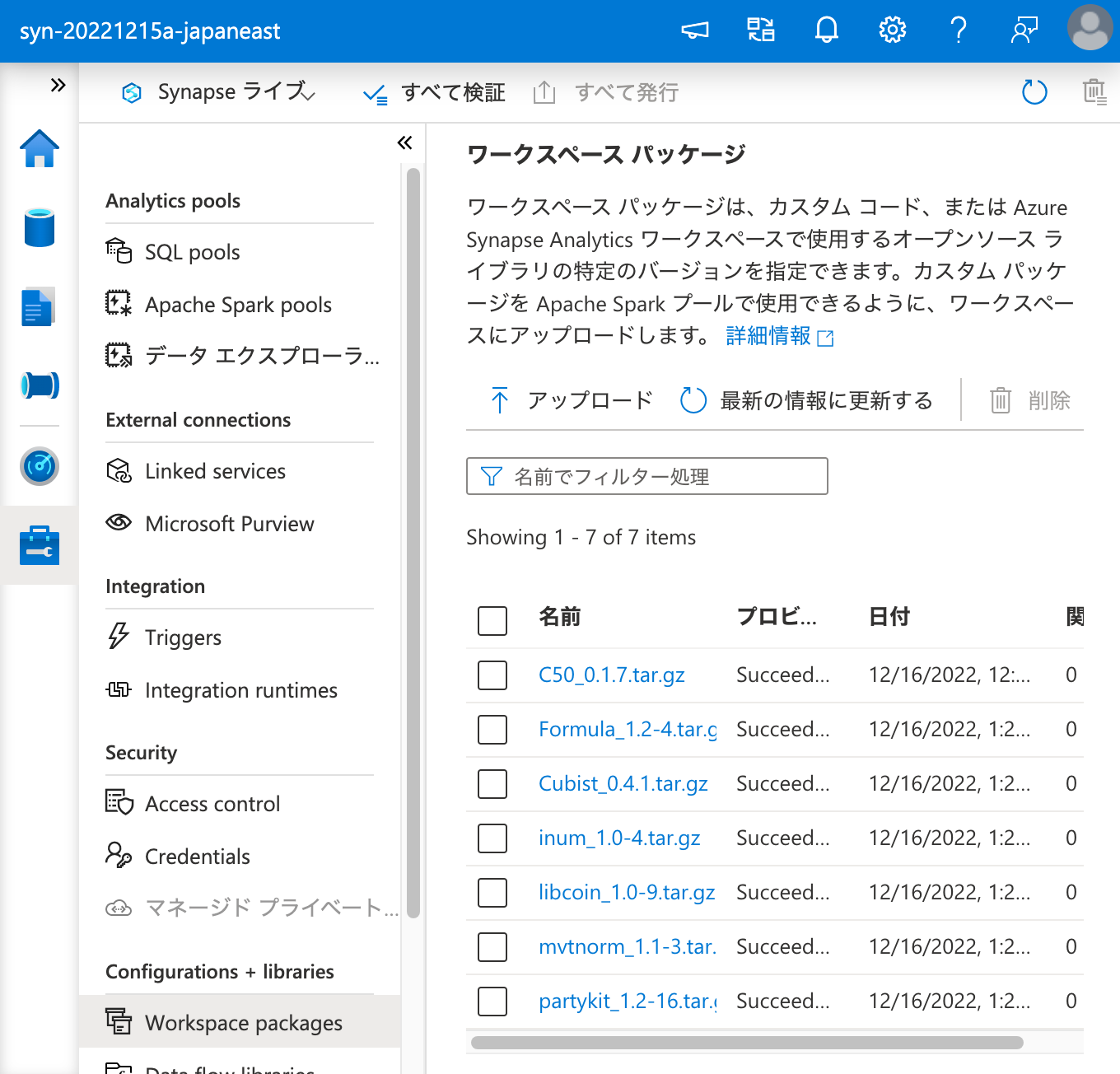
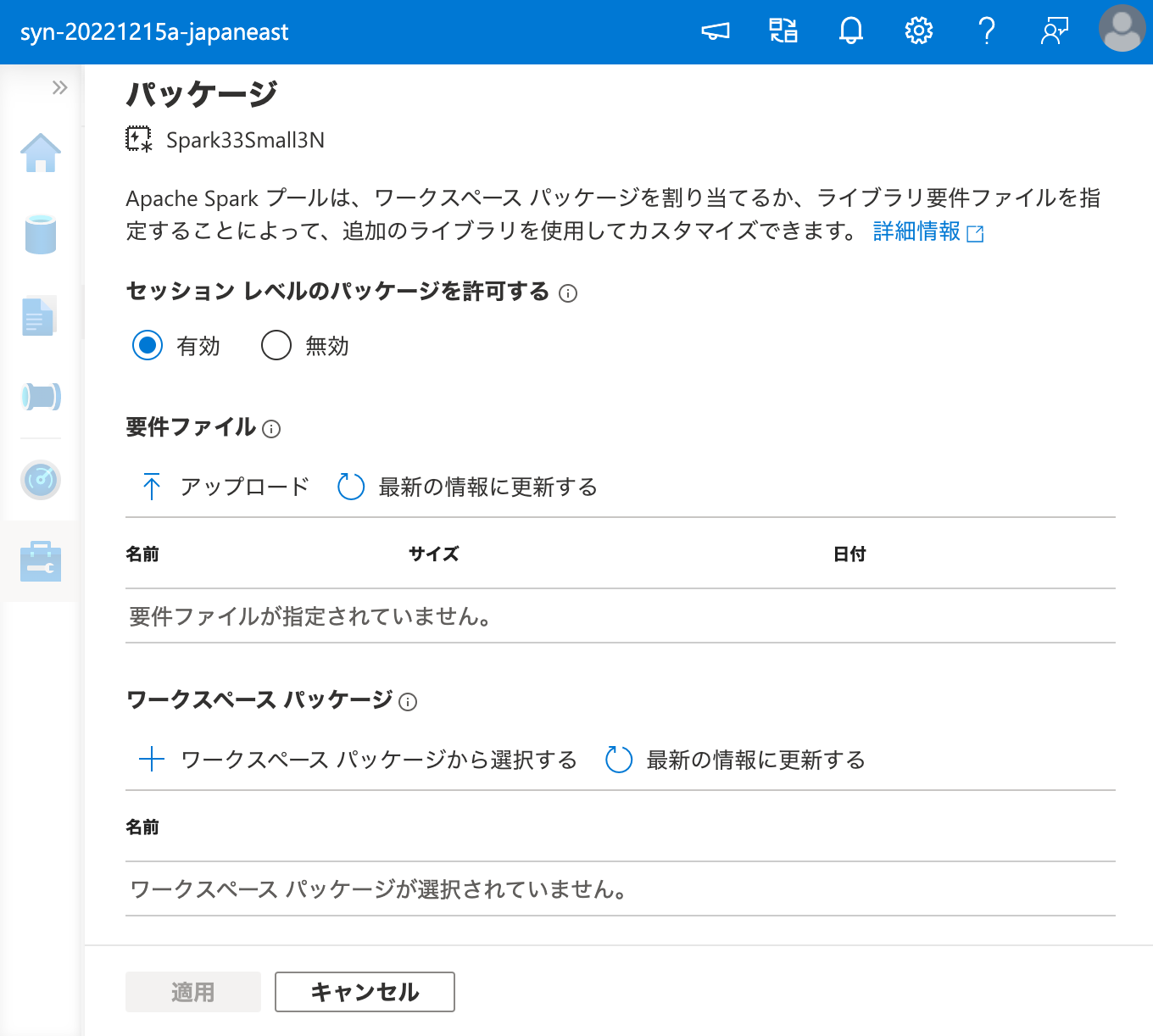
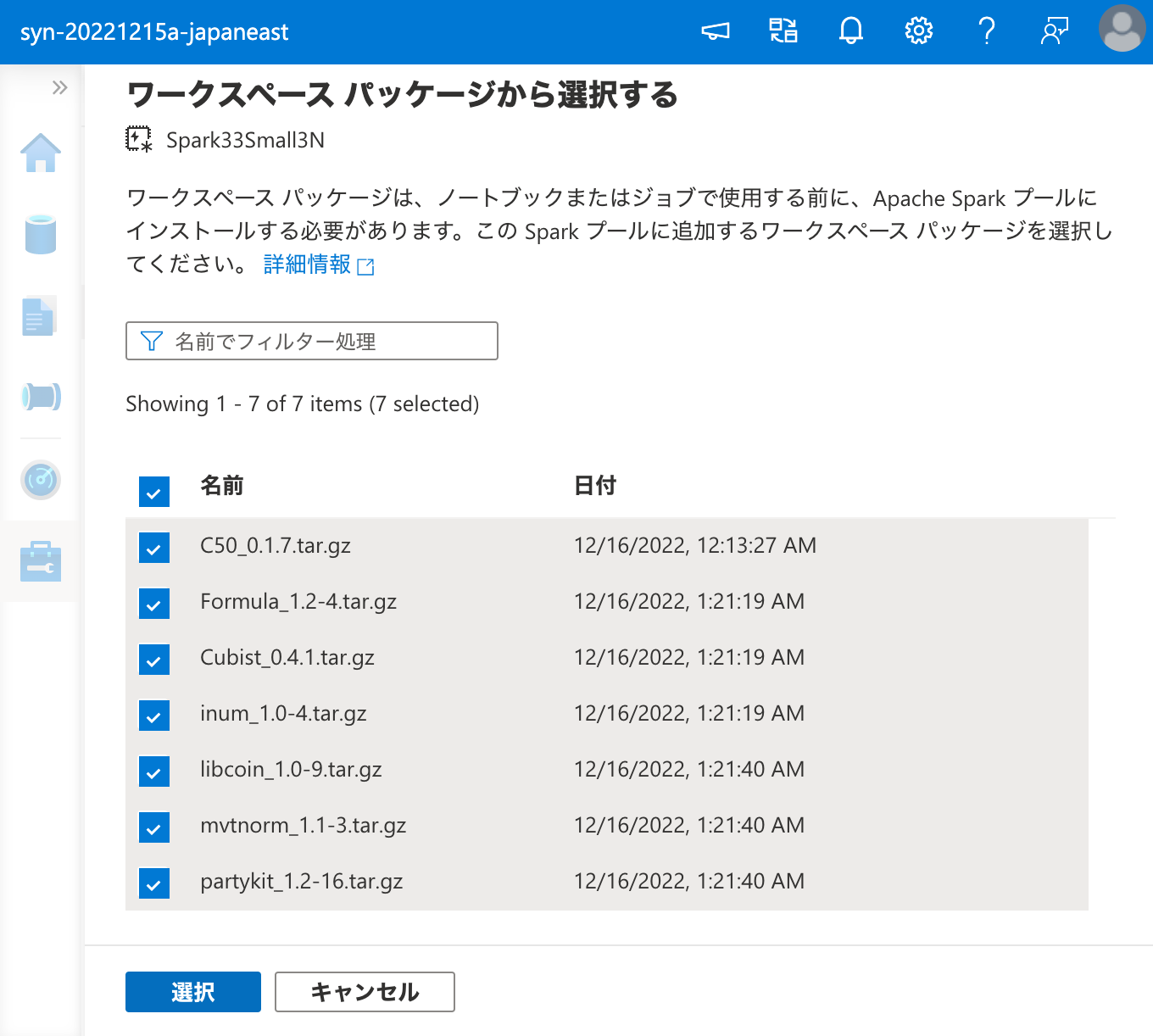
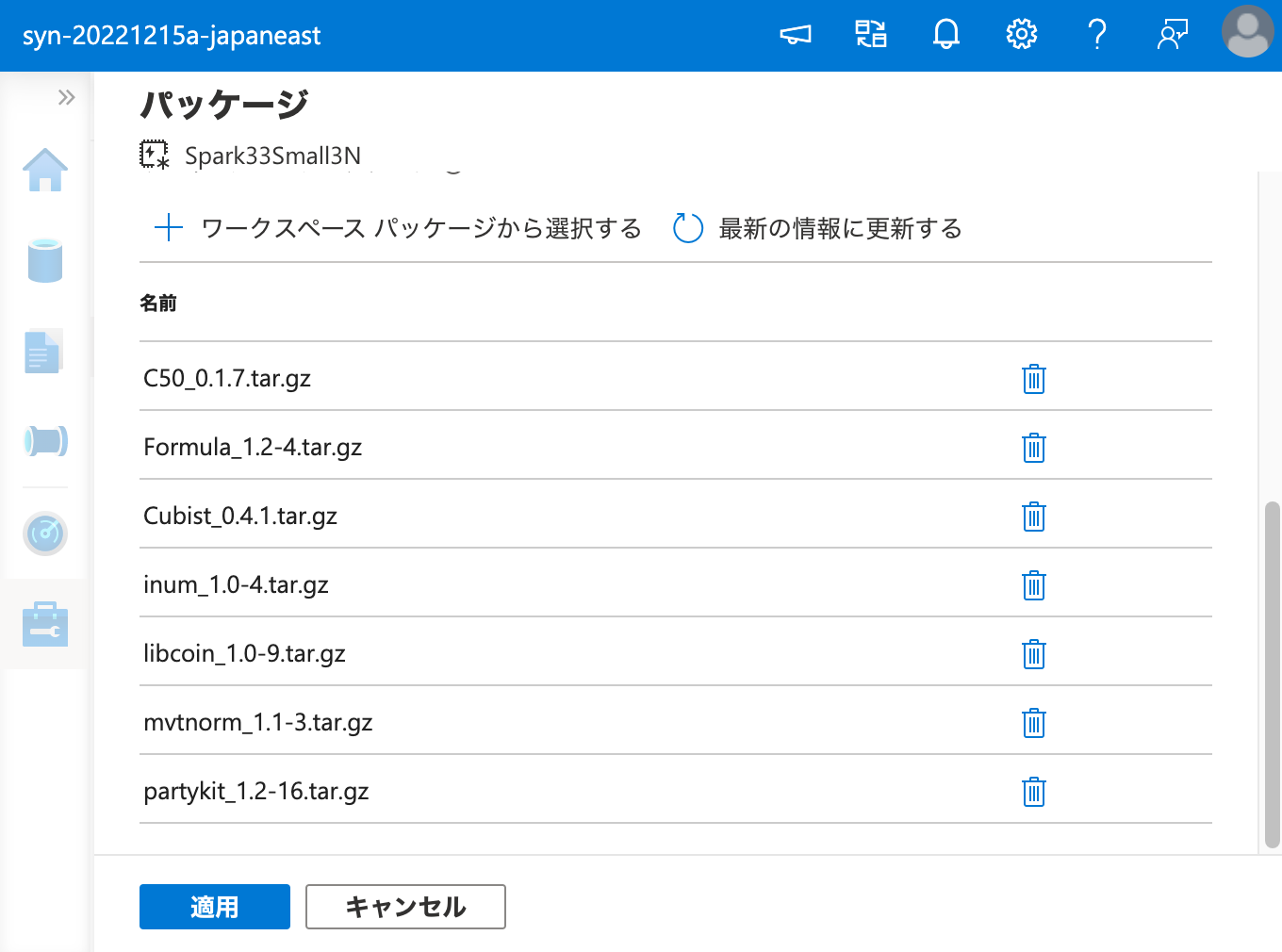
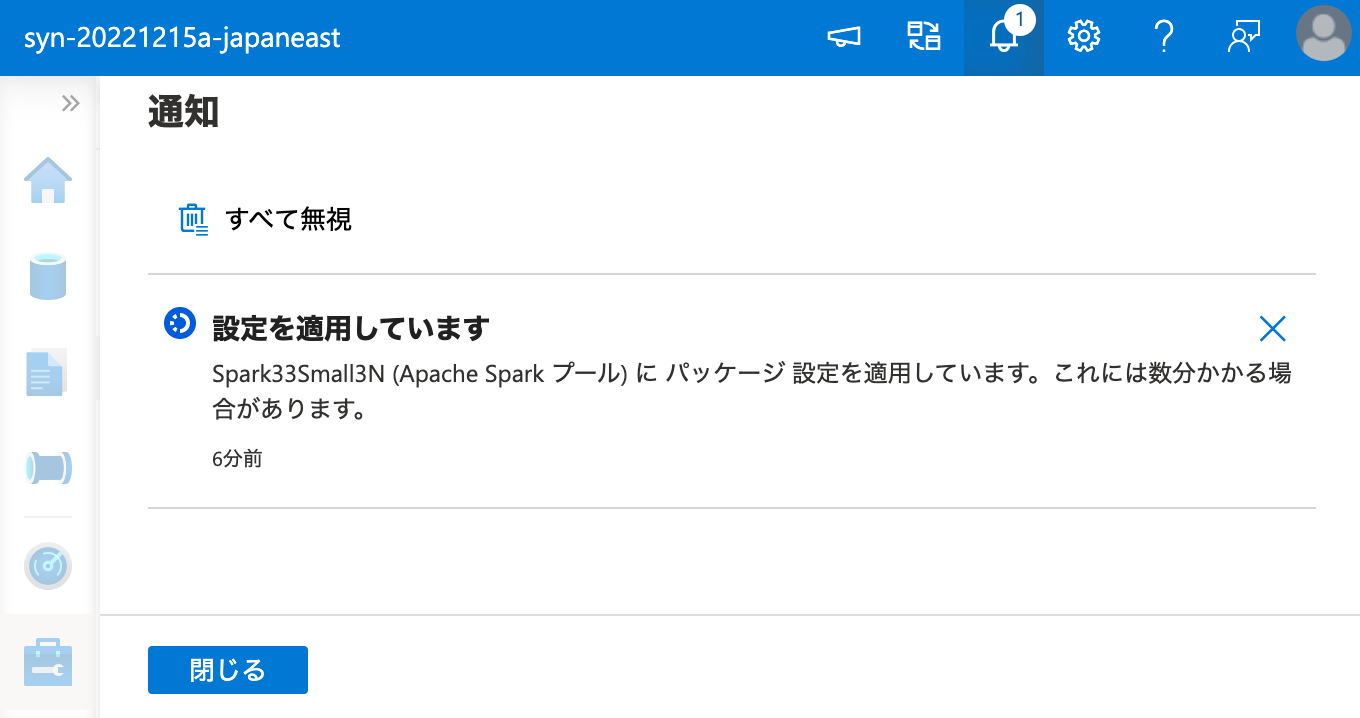
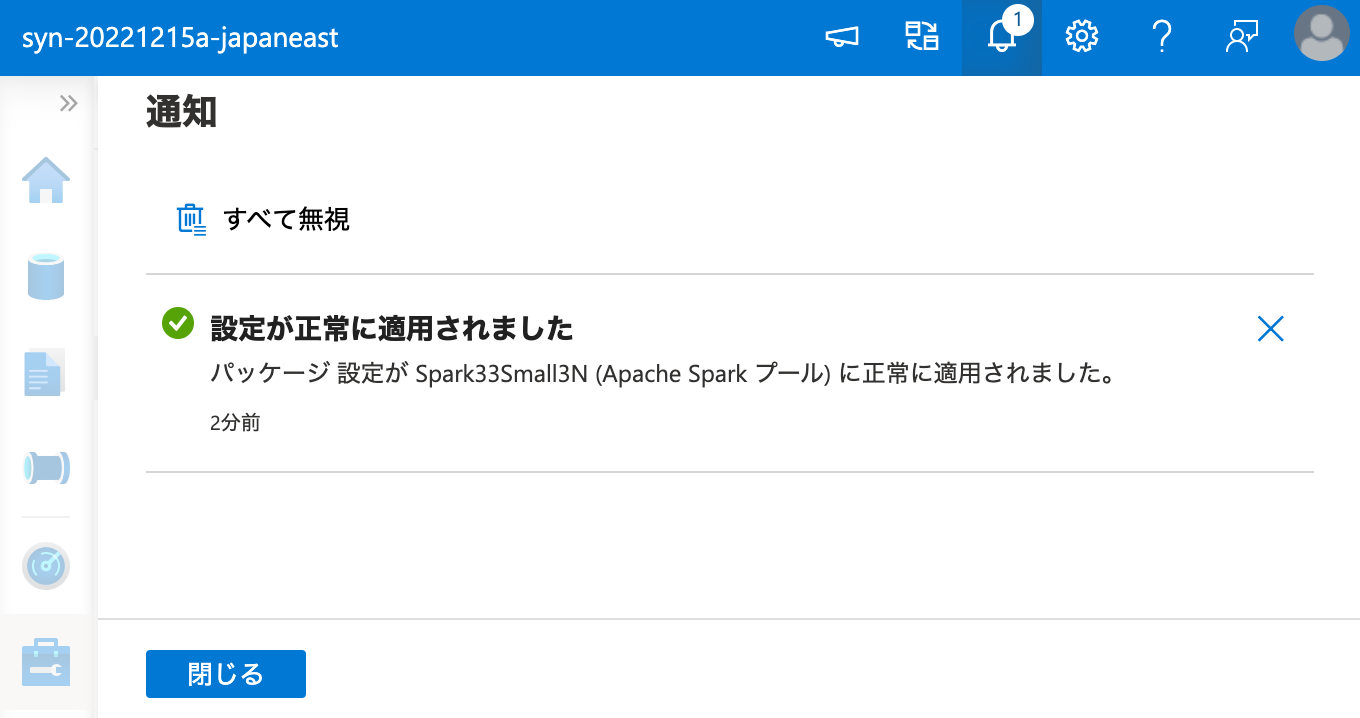
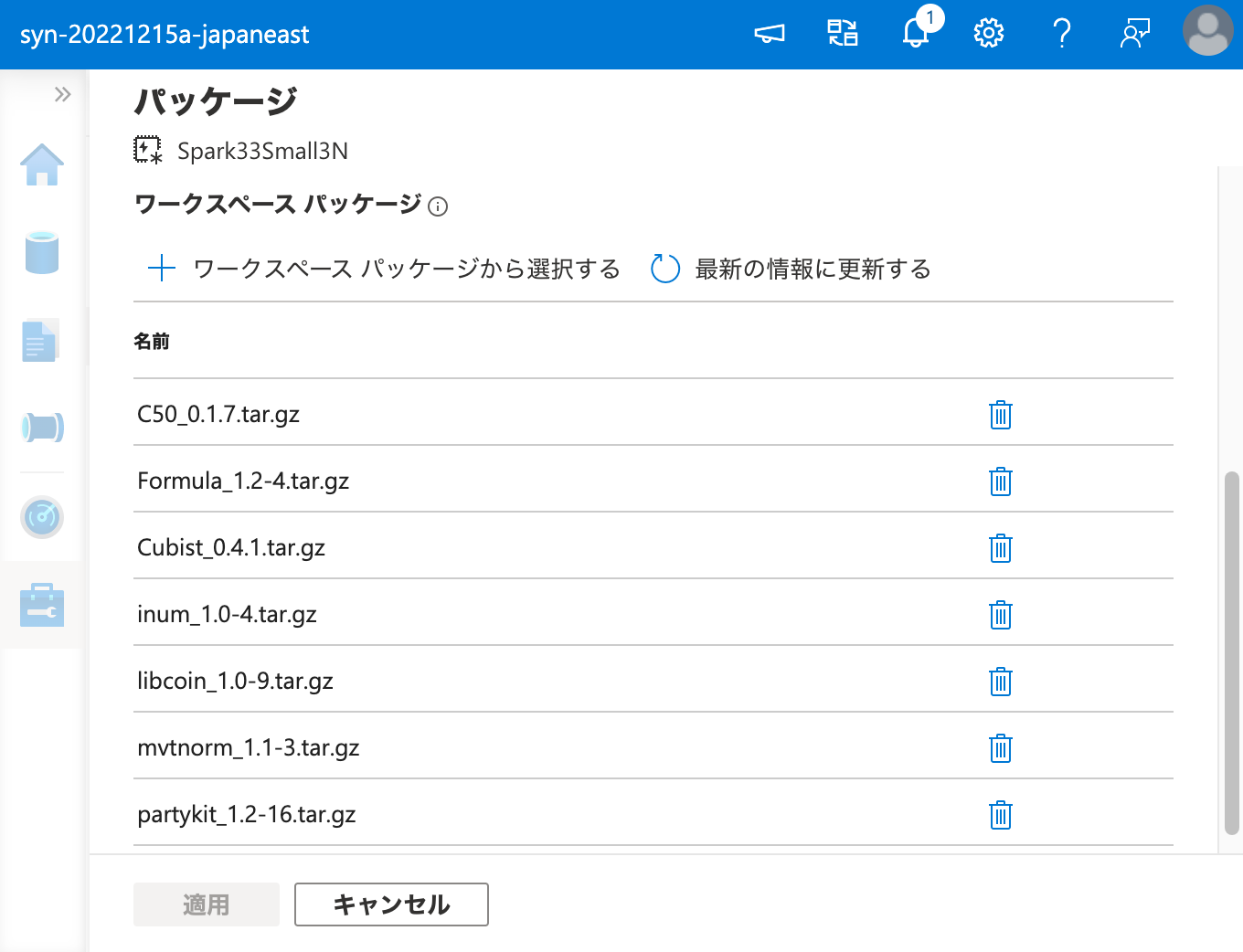
インストールに成功しました。それでは、ワークスペース パッケージ からインストールしたパッケージを、ノートブックから呼び出してみましょう。
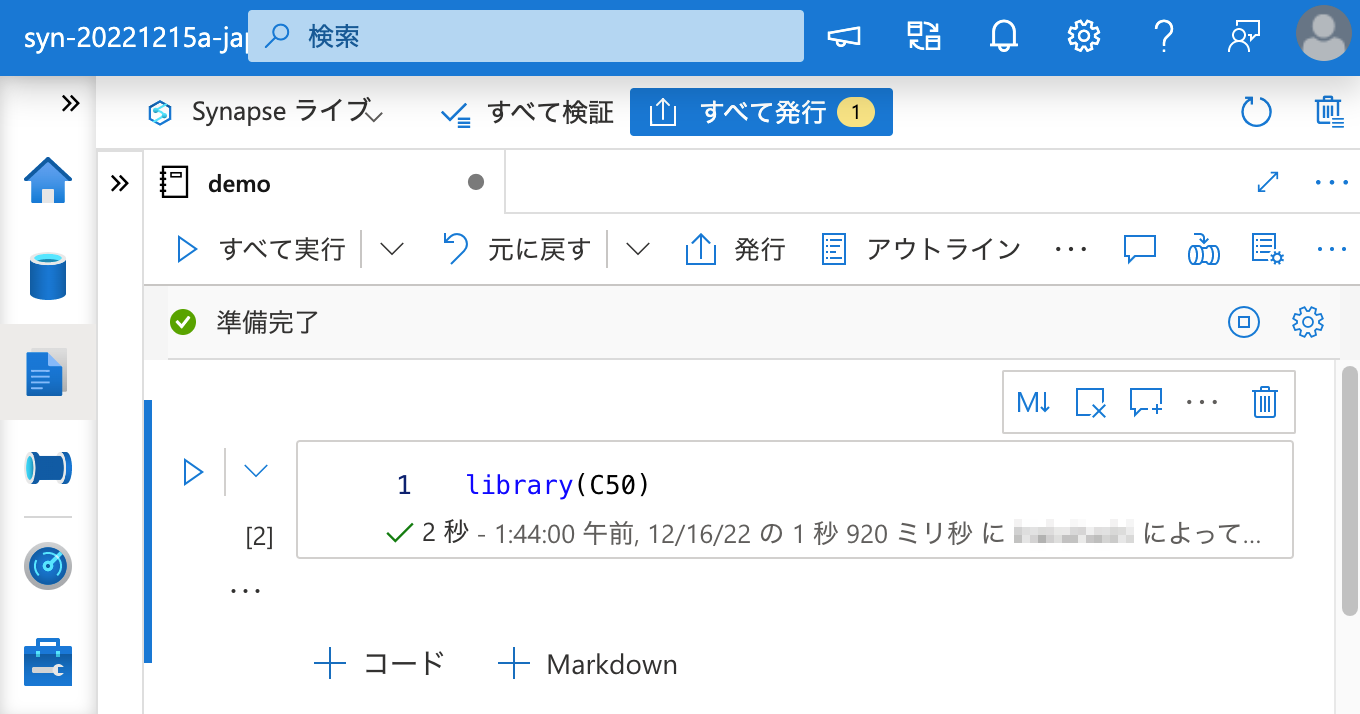
成功です。
最後に、セッションを一度終了しても、ワークスペース パッケージ としてインストールされたパッケージが再度利用できることを確認しておきましょう。
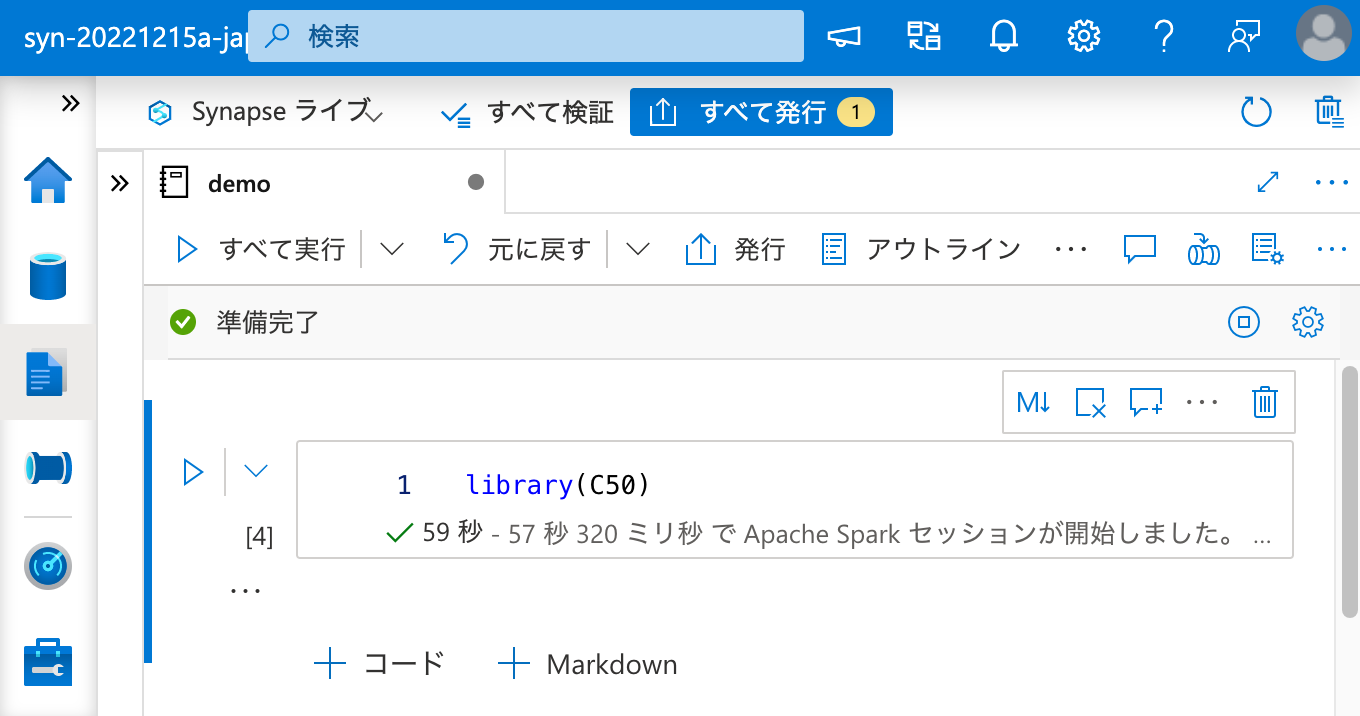
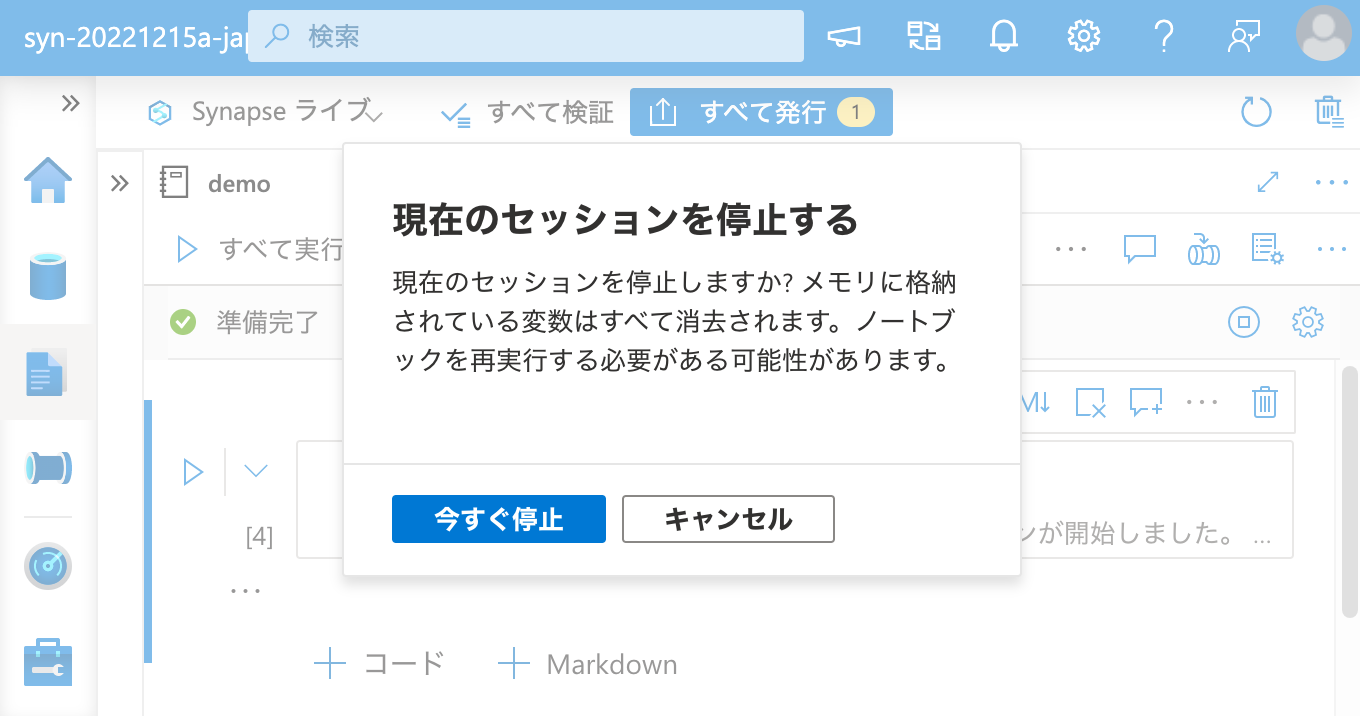
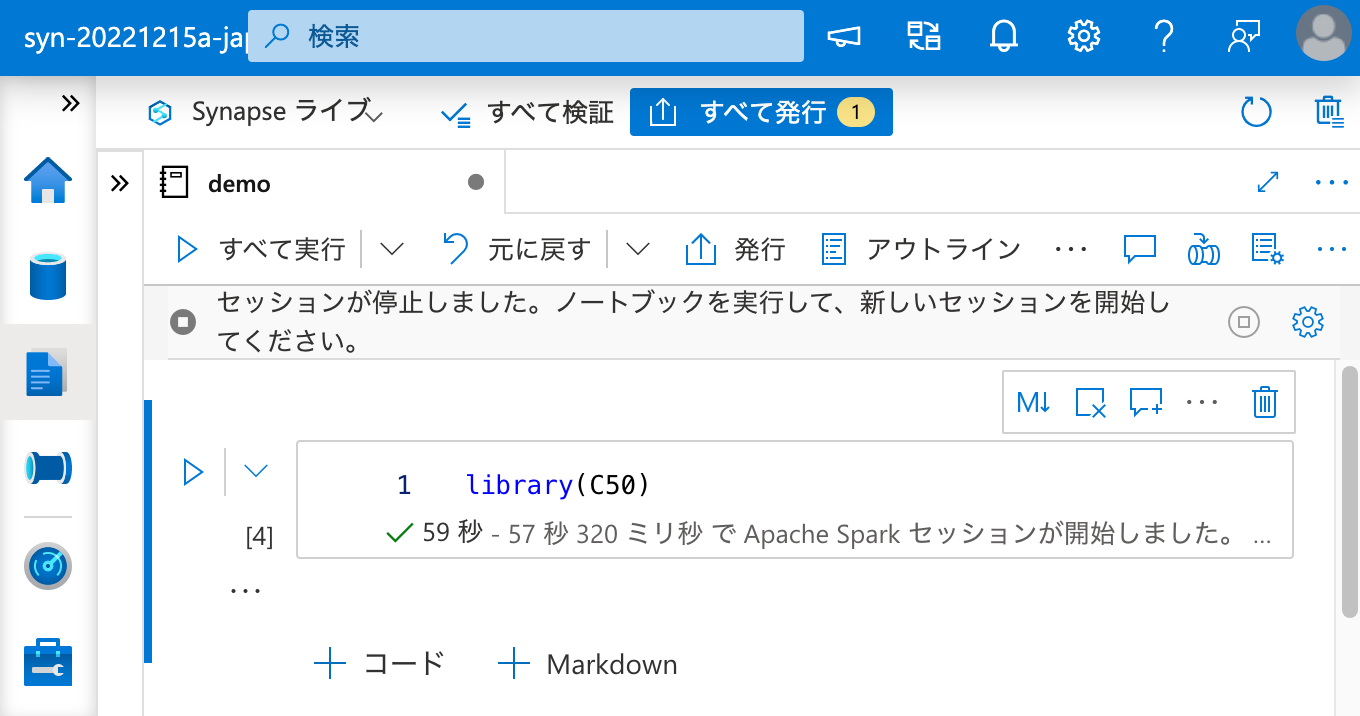
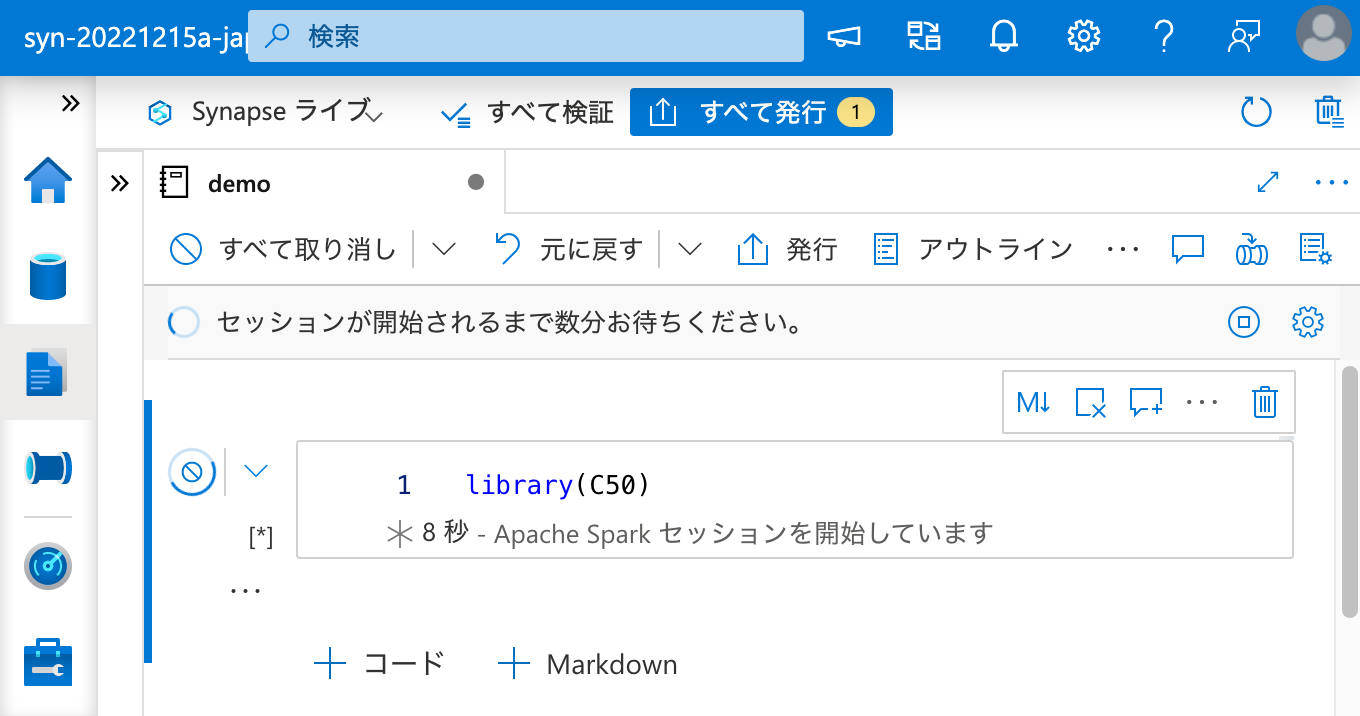
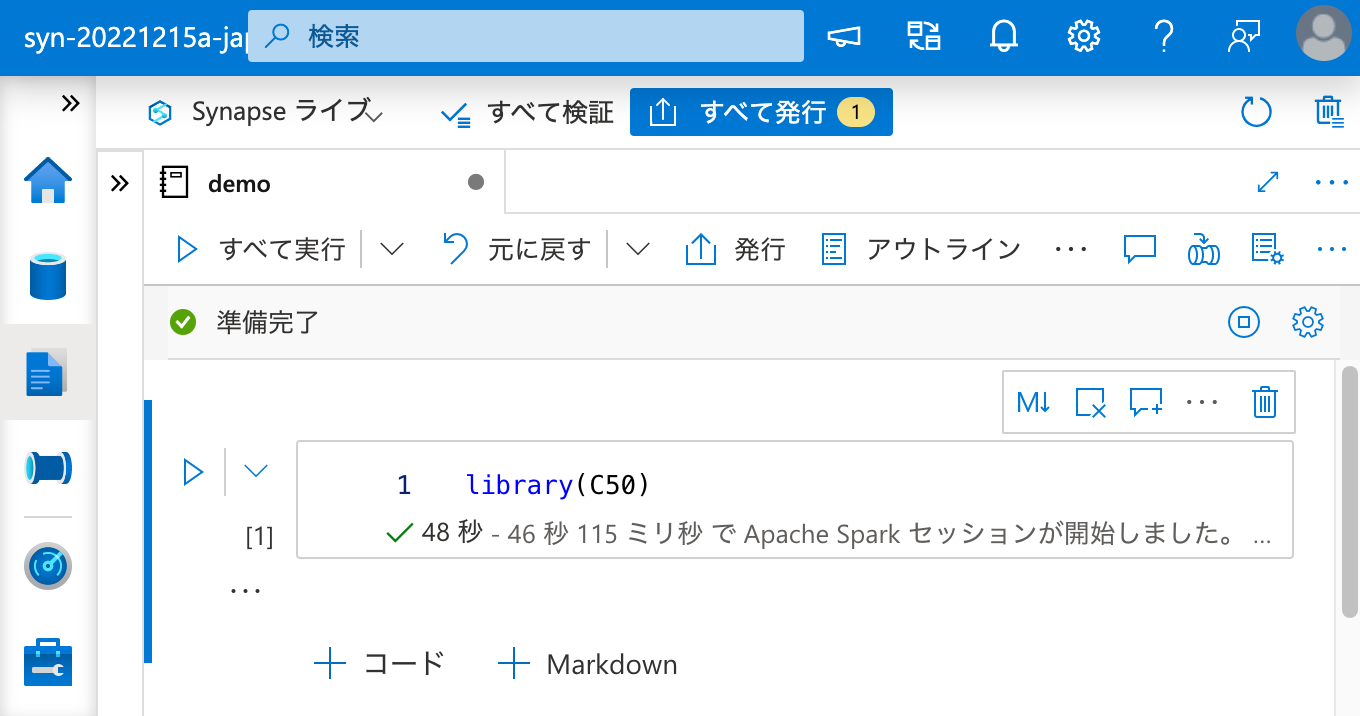
問題ありません。これで、Apache Spark クラスターとのセッション状態とは関係無く、R パッケージを恒久的に利用できるようになりました。
まとめ
Azure Synapse Analytics の Apache Spark プール で R言語を利用する場合、かつ自前のパッケージをインストールしたり ワークスペース パッケージ を利用する場合に、自分で依存関係を解決する方法を解説しました。
少し回り道にはなりますが、一度 ノートブック セッション パッケージ として CRAN 等を使ってインストールすることで、依存パッケージをバージョンや URI も含めて特定することができ、誰でも簡単に R パッケージのインストールを恒久化することができます。
Azure Synapse Analytics 上で R によるデータ分析をゴリゴリやる方には必須知識だと思いますので、ぜひお役立てください。